
Build and deploy a multi-file, multi-format RAG App to the Web

DEVELOPING THE APP
Build and Deploy a Multi-File, Multi-Format RAG App to the Web
Part 1 — Developing the code using Python, Gradio, GROQ & LlamaIndex
This is the first of a two-part series of articles. In this part (Part 1) I’ll show you how to develop a useful Web app that can upload and read many different types of file e.g. PDF, TXT, DOCX etc … We’ll then use AI and RAG to analyse the files and answer questions on them.
In part 2, I’ll show you how you can use Hugging Face Spaces to deploy your app to the web so the rest of the world can marvel at your greatness.
PS. If you want a sneak peek at the deployed app on Hugging Face Spaces, click on this link
Undoubtedly, one of the largest growth areas to come out of AI and large Language Models is the field of Retrieval Augmented Generation (RAG). RAG is a fine-tuning method, where you provide an LLM with specific information it didn’t have access to in its training data.
If you’ve never heard of RAG before, don’t worry, it’s not that complicated. A typical RAG pipeline entails reading in one or more (usually PDF format) documents, but they can be CSV, TXT, or whatever. Splitting these document(s) into smaller chunks of text, encoding each token (kinda like an individual word, but can be smaller/larger) in the chunks with a numeric value and finally storing this numeric data in a database.
When a user asks a question about the document(s), a similar process happens to their question. It’s split up into individual tokens, each of which is assigned a numeric value using the same encoding process that was done on the original file text. The numeric values of the tokens in the user’s question are compared to the numeric values of the tokens in the chunks of the original documents. The closer they match, the more likely it is that the document chunk relates to the user question. The LLM will then use that fact to narrow down its list of possible answers before displaying the most likely response to the user.
And that process is why RAG is so important.
For example, using RAG can give companies access to automated systems to investigate and query reams of information contained in their internal documents. That automation can also be surfaced to staff members via company intranets, or even to customers via automated help desk functionality built into external websites. All this can add value to the company’s bottom line.
In the rest of this article, we’ll build a Minimum Viable Product of a Web application that will perform RAG on documents uploaded to it.
Our app will be able to deal with multiple file uploads and be able to mix and match different file formats including Microsoft EXCEL and Word, PDF and Text.
We’ll use Gradio for the GUI and Groqas our interface to an LLM and LlamaIndex as our RAG agent.
I’ve written about Groq, LlamaIndex and Gradio before, so check out those links if you need a refresher on what they’re all about.
Get a GROQ API key
You’ll need a free GROQ API key for the code we'll develop. Click this link and sign in or register as required.
On the left-hand side of the screen, click on the API Keys link, then click on the Create API Key button that appears. After this, enter a name for your key, hit Submitand Groq will create a key for you. Take note of this key as you’ll need it later. If you forget it, just create another one when you require it.
Setting up a dev environment
I’ll be coding the app on Linux (Ubuntu) on a Jupyter notebook. If you’re a Windows user, I recommend installing WSL2 Ubuntu.
Check out the link below for my comprehensive tutorial on installing WSL2 Ubuntu on Windows.
Installing WSL2 Ubuntu for Windows
It’s best to set up a separate development environment when we start coding a new project. That will keep our projects siloed and help ensure that anything we set up in terms of different versions of Python or external libraries won’t “cross contaminate” other projects.
I use conda for that purpose but use whatever method suits.
If you want to go down the conda route and you don’t already have it, you will have to install Miniconda (recommended) or Anaconda first.
You can download MiniConda here.
Once the environment is created, switch to it using the activate command, and then we can install Jupyter and the required Python libraries.
# create our dev environment
(base) $ conda create -n gradio_rag python=3.11
# switch to it
(base) $ conda activate gradio_rag
# install extra libraries required
(gradio_rag) $ pip install gradio groq jupyter
(gradio_rag) $ pip install llama-index-llms-groq llama_index
(gradio_rag) $ pip install llama-index-embeddings-huggingface
Now type in jupyter notebook into your command prompt. You should see a Jupyter Notebook open in your browser. If that doesn’t happen automatically, what you’ll likely see is a screenful of information after the jupyter notebook command. Near the bottom of that output, there will be a URL that you should copy and paste into your browser to initiate the Jupyter Notebook.
Your URL will be different to mine, but it should look something like this:-
http://127.0.0.1:8888/tree?token=3b9f7bd07b6966b41b68e2350721b2d0b6f388d248cc69da
The GUI interface
The Gradio web interface to our app will be straightforward and consist of just 6 widgets.
The top half of the screen has two big components, the one on the left allows you to Select files to load from your local filesystem (you can also drag and drop into here too). Once you have done that, you click on the large button labelled Load Documents. This kicks off the RAG process. Once that’s done you will see a confirmation message appear in the Load Statusmessage box stating which files have been loaded and processed.
After that, you can input your query into the Enter Your Question input box and the answer will appear in the large Chatbot display box near the bottom of the screen.
The final component is a simple Clear button at the bottom which does what it says on the tin.
The Code
1/ Import required libraries
import os
import warnings
import gradio as gr
imprt groq
import asyncio
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.groq import Groq
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
2/ Initialisation
# A warning may appear which doesn't
# affect the operation of the code
# Suppress it with this code
warnings.filterwarnings("ignore", message=".*clean_up_tokenization_spaces.*")
# Global variables
index = None
query_engine = None
# Set up Groq API key
os.environ["GROQ_API_KEY"] = "YOUR_GROQ_API_KEY"
# Initialize Groq LLM and ensure it is used
llm = Groq(model="mixtral-8x7b-32768")
Settings.llm = llm # Ensure Groq is the LLM being used
# Initialize our chosen embedding model
embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L6-v2")
3/ RAG Functions
# These are our RAG fucntions, called in response to user
# initiated events e.g clicking the Load Documents button
# on the GUI
#
def load_documents(file_objs):
global index, query_engine
try:
if not file_objs:
return "Error: No files selected."
documents = []
document_names = []
for file_obj in file_objs:
document_names.append(file_obj.name)
loaded_docs = SimpleDirectoryReader(input_files=[file_obj.name]).load_data()
documents.extend(loaded_docs)
if not documents:
return "No documents found in the selected files."
# Create index from documents using Groq LLM and HuggingFace Embeddings
index = VectorStoreIndex.from_documents(
documents,
llm=llm, # Ensure Groq is used here
embed_model=embed_model
)
# Create query engine
query_engine = index.as_query_engine()
return f"Successfully loaded {len(documents)} documents from the files: {', '.join(document_names)}"
except Exception as e:
return f"Error loading documents: {str(e)}"
async def perform_rag(query, history):
global query_engine
if query_engine is None:
return history + [("Please load documents first.", None)]
try:
response = await asyncio.to_thread(query_engine.query, query)
return history + [(query, str(response))]
except Exception as e:
return history + [(query, f"Error processing query: {str(e)}")]
def clear_all():
global index, query_engine
index = None
query_engine = None
return None, "", [], "" # Reset file input, load output, chatbot, and message input to default states
4/ The Gradio interface
# Create the Gradio interface
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.Markdown("# RAG Multi-file Chat Application")
with gr.Row():
file_input = gr.File(label="Select files to load", file_count="multiple")
load_btn = gr.Button("Load Documents")
load_output = gr.Textbox(label="Load Status")
msg = gr.Textbox(label="Enter your question")
chatbot = gr.Chatbot()
clear = gr.Button("Clear")
# Set up event handlers
load_btn.click(load_documents, inputs=[file_input], outputs=[load_output])
msg.submit(perform_rag, inputs=[msg, chatbot], outputs=[chatbot])
clear.click(clear_all, outputs=[file_input, load_output, chatbot, msg], queue=False)
5/ Finally we can call the app
# Run the app
if __name__ == "__main__":
demo.queue()
demo.launch()
The app as it stands can cope with PDF, CSV and TXT documents. To read other file types, you may have to install additional libraries. For example, when I first tried to load a Microsoft Word Doc file, I received this error.
Error loading documents: docx2txt is required to read Microsoft
Word files: `pip install docx2txt`
When I did the pip command as directed, the app was able to read the .docx file and answer questions on it.
To read Excel files, pip install openpyxl
pip install openpyxl
Test drive
Let’s take it for a spin. I have a PDF, a text file, and an Excel document which you can view on Dropbox if you like.
A Text file about Elephants
===========================
https://www.dropbox.com/scl/fi/mjtaqfhz5g3bdob8ob9c0/storm_gen_article_polished.txt?rlkey=bhbnjrm6ejolri35drgln8llt&st=o6lpox18&dl=0
The Introduction to DropBox PDF
===============================
https://www.dropbox.com/scl/fi/z3fne9w9x6ujy0hkv0r2l/Get-Started-with-Dropbox.pdf?rlkey=jsngq3g91bvv4lffcuf8otvg5&st=mhqz60j0&dl=0
Fake sales data in XL format
============================
https://www.dropbox.com/scl/fi/3yp85yn375sze5n1ovnhf/sales_data.xlsx?rlkey=thm8l60739xi5kxon0zpoe1cx&st=g8w49f9p&dl=0
Here’s a little excerpt from all three.
Elephants text file sample
...
...
# Etymology
The term "elephant" is derived from the Latin "elephas" (genitive "elephantis")
, which originates from the Greek word "ἐλέφας" (elephas, genitive "ἐλέφαντος"
(elephantos)), with a meaning that has been variously interpreted as 'ivory'
or 'elephant'. Historical linguistic studies ...
...
Excel Sales File Sample
order_id order_dat customer customer product_i product_n category quantity price total
0 1/7/2023 588 Customer 202 Desk Office 5 323.59 1617.95
1 4/17/2023 630 Customer 202 Desk Office 3 280.16 840.47
2 9/25/2023 230 Customer 207 Pen Office 4 491.93 1967.72
3 3/8/2023 318 Customer 206 Paper Office 8 477.71 3821.64
4 1/10/2023 383 Customer 207 Pen Office 1 81.06 81.06
5 4/24/2023 126 Customer 200 Laptop Electronic 4 250.64 1002.58
6 9/20/2023 641 Customer 203 Chair Office 3 548.67 1646.01
7 8/24/2023 166 Customer 203 Chair Office 6 377.07 2262.44
8 ######## 769 Customer 203 Chair Office 4 99.12 396.48
9 8/5/2023 902 Customer 206 Paper Office 8 254.36 2034.89
10 1/13/2023 549 Customer 203 Chair Office 10 569.41 5694.13
...
...
Intro to Dropbox PDF sample
...
...
Send Large Files
Need to send a file? Just add it to your Dropbox, share a link
to it, and you’re done. No matter how large the file is, anyone
with the link can view or download a copy — even if they
don’t have a Dropbox account.
On dropbox.com
1. Sign in to dropbox.com, and find the file or folder you’d like to share.
2. Hover over the file or folder, and click the Share button that appears.
3. Enter the email addresses of the people you want share a file with,
and click Send. Or click Create a link to share with anyone, even
if they don’t use Dropbox. You can copy and paste the link into an
email, instant message, or wherever you’d like people to access it.
...
...
When running, the app should look like this. Click the top left button to include the files you want to analyse (or drag and drop them into the box). The files can be a mixture of text, PDF, DOCX or XLSX. Next, click the Load Documents button. The Load status message box will update when the files have been processed. Then you can type in the question you want answered, hit Return, and the answer should be displayed in the Chatbot window.
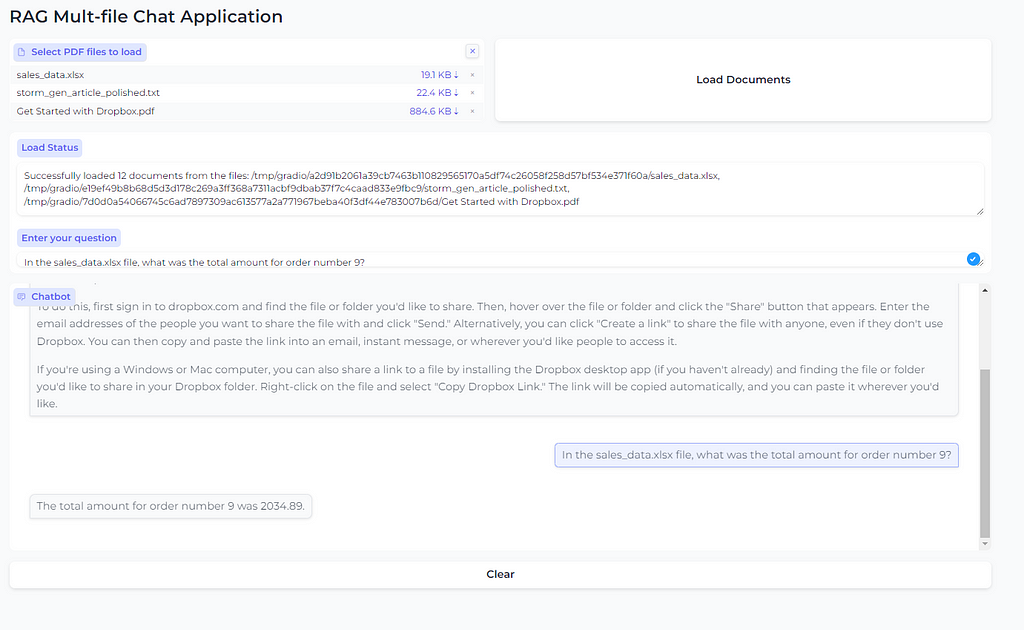
For my first question, I targeted the text file on Elephants by asking this.
What is the etymology of the word Elephant?
The term “elephant” is derived from the Latin “elephas” (genitive “elephantis”), which originates from the Greek word “ἐλέφας” (elephas, genitive “ἐλέφαντος” (elephantos)), with a meaning that has been variously interpreted as ‘ivory’ or ‘elephant’. Historical linguistic studies trace the word back through various forms in ancient languages, suggesting that the name for the animal and the material of its tusks have been closely associated for millennia. The ancient Greeks and Romans adopted the term from earlier civilizations, possibly through Phoenician intermediaries, who themselves borrowed it from languages of the Near East or Africa. This etymological journey reflects the widespread fascination with elephants and the long-distance trade in ivory, which connected civilizations across continents from a very early period. The evolution of the word “elephant” into the English language also encapsulates the animal’s significance in culture, religion, and economy throughout history. In many cultures, elephants have been revered as symbols of wisdom, strength, and memory, and the etymology of the word “elephant” mirrors the deep respect and value humans have attributed to these majestic creatures. The historical linguistic path of the term also sheds light on the ancient global trade networks and cultural exchanges, highlighting the elephant’s impact on human societies across the world.
This answer was taken straight from the uploaded doc. Spot on.
The next question was about querying the PDF.
How do I send a large file using Dropbox?
To send a large file using Dropbox, you can add the file to your Dropbox and share a link to it. This allows anyone with the link to view or download a copy of the file, even if they don’t have a Dropbox account. To do this, you can follow these steps:
Install the Dropbox desktop app if you haven’t already.
Open your Dropbox folder, and find the file or folder you’d like to share.
Right-click on the file and select “Copy Dropbox Link.” The link will be copied automatically.
Just paste the link wherever you’d like people to access it.
Alternatively, you can also share a link to a file through the Dropbox website:
Sign in to dropbox.com, and find the file or folder you’d like to share.
Hover over the file or folder, and click the “Share” button that appears.
Click “Create a link” to share with anyone, even if they don’t use Dropbox. You can copy and paste the link into an email, instant message, or wherever you’d like people to access it.
Another great answer there.
My final question was on the Excel file. I had to reference the input file in the question before the model was able to get the correct answer.
In the sales_data.xlsx file, what was the total amount for order number 9?
The total sales amount for order number 9 was 2034.89.
Summary
In this article, I’ve shown how to build a cool multi-file format Retrieval Augmented Generation (RAG) Web App using Gradio, GROQ, and LlamaIndex. I highlighted why RAG is a game-changer, as it fine-tunes large language models (LLMs) by feeding them information they didn’t have when they were first trained.
We also went through setting up a development environment with Conda, what our external library requirements were and how to get a GROQ API key.
We then looked at the different parts of our app. Gradio for the front end, and hooking up GROQ and LlamaIndex for the heavy lifting in the back end.
So, I hope this article will be a handy guide for any developer eager to get RAG into their apps, mixing both the why and the how into a neat package.
Look out for Part 2 soon, where I show step-by-step how to deploy the app to the World Wide Web using Hugging Face Spaces.
OK, that’s all for me just now. I hope you found this article useful. If you did, please check out my profile page at this link. From there, you can see my other published stories, follow me or subscribe to get notified when I post new content.
I know times are tough and wallets constrained, but if you got real value from this article, please consider buying me a wee dram.
I think you’ll find these articles interesting if you like this content.
Build and deploy a multi-file, multi-format RAG App to the Web was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/hfk9mMn
via IFTTT


