
ETL Pipelines in Python: Best Practices and Techniques
Strategies for Enhancing Generalizability, Scalability, and Maintainability in Your ETL Pipelines

Produtora Midtrack and obtained from Pexels.com
When building a new ETL pipeline, it’s crucial to consider three key requirements: Generalizability, Scalability, and Maintainability. These pillars play a vital role in the effectiveness and longevity of your data workflows. However, the challenge often lies in finding the right balance among them — sometimes, enhancing one aspect can come at the expense of another. For instance, prioritizing generalizability might lead to reduced maintainability, impacting the overall efficiency of your architecture.
In this blog, we’ll delve into the intricacies of these three concepts, exploring how to optimize your ETL pipelines effectively. I’ll share practical tools and techniques that can help you enhance the generalizability, scalability, and maintainability of your workflows. Additionally, we’ll examine real-world use cases to categorize different scenarios and clearly define the ETL requirements needed to meet your organization’s specific needs.
Generalizability
In the context of ETL, generalizability refers to the ability of the pipeline to handle changes in the input data without extensive reconfiguration. This is a highly desirable property because its inherent flexibility can save you significant time in your work. This flexibility is especially beneficial when many data stakeholders are involved in providing input data. The more people involved, the greater the likelihood of changes in the incoming data sources.
Furthermore, if you want to reuse your pipeline for different projects, generalizability allows for quick adaptation to meet the specific requirements of each new project. This capability not only enhances efficiency but also ensures that your ETL processes remain robust and responsive to evolving data needs.
To gain a more concrete understanding of what generalizability actually means, I would like to provide you with a simple example of a small pipeline that is absolutely not generalizable. This example involves sales data for a product that the senior leadership team is interested in reviewing every year.
sales = pd.DataFrame({
'Year': [2019, 2020, 2021, 2022, 2023],
'Sales': [30000, 25000, 35000, 40000, 45000]
})
The leadership team always discusses the sales data for the respective year at the end of each year. At the end of 2023, they ask you to provide the numbers for that year. A non-generalizable approach to delivering this data would involve a simple filtering solution, where you would filter the dataset to only include records for the year 2023.
sales[sales['Year'] == 2023]
This pipeline is not generalizable at all. Next year, you would need to run the code again and manually change the year from 2023 to 2024. For our use case, it would be more generalizable if we constructed our pipeline to automatically retrieve the sales data for the highest available year.
sales[sales['Year'] == sales['Year'].max()]
By making a single adaptation, you can avoid having to go into the code every year to change the year number. This adjustment allows the pipeline to automatically select the sales data for the most recent available year.
Of course, in this example, it’s not a significant change. However, in reality, pipelines can be much larger, and adjusting a number or a string in 30 different places can become quite time-consuming. This situation becomes even more complicated when changes are unexpected, such as when columns are renamed in the system or the data type of a column changes. Thus, there are several aspects to consider for generalizability.
But what can we do to make our pipelines more generalizable? Unfortunately, there isn’t a one-size-fits-all recipe for enhancing generalizability in our workflows. Each use case is unique, and therefore, solutions must be tailored accordingly. However, there are some tips and tricks that can be applied to various problems.
- Avoid Hardcoding: Hardcoding involves entering specific values directly into your expressions, as we did in our sales example. Instead, aim to use dynamic expressions that can adapt to changes in the data.
- Use Mapping Tables: If you anticipate that column headers may vary, consider creating a dictionary or a mapping table to handle potential variations. This allows you to rename columns dynamically based on the names that could occur in the dataset.
# Mapping table (dictionary) for renaming
column_mapping = {
'SALES': 'Sales',
'Revenue': 'Sales',
'Sales_2023': 'Sales'
}
# Rename columns using the mapping table
df_renamed = df.rename(columns=column_mapping)
- Utilize Regex: Similar to using mapping tables, regex can be employed to rename column headers dynamically. The advantage of the regex approach is that you don’t necessarily need to know how the headers will change. Instead, you can define a pattern that captures potential variations and rename all relevant columns to your desired name accordingly.
import pandas as pd
import re
# Regex pattern for possible variations of "Sales"
pattern = r"(?i)(.*sales.*|.*verkäufe.*)" # Case-insensitive, also match "Verkäufe" in German
# Find columns matching the pattern
sales_column = [col for col in df.columns if re.match(pattern, col)]
# Rename the matching columns
for col in sales_column:
df.rename(columns={col: 'Sales'}, inplace=True)
- Force Data Types: ETL pipelines can encounter issues when a column expected to be numerical is changed to a string. This can lead to failures in certain aggregation functions or mathematical operations. To mitigate this, Pandas provides useful functions to enforce specific data types. Any values that cannot be converted will be replaced with NaN. Additionally, you can define the data type when loading the data by using the dtype parameter.
# Convert to numeric, forcing invalid values to NaN
df['col2'] = pd.to_numeric(df['col2'], errors='coerce')
# Convert to datetime, forcing invalid dates to NaT
df['date_col'] = pd.to_datetime(df['date_col'], errors='coerce')
# Specify data types while reading a CSV file
df = pd.read_csv('data.csv', dtype={'col1': int, 'col2': float, 'col3': str})
- Coverage of Different Scenarios: If you have a clear understanding of which parts of your pipeline need to be more generalizable, you can implement if-else logic to handle various inputs. While this can enhance generalizability, it often comes at the cost of scalability and maintainability.
- Use Configuration Files: Store pipeline configurations — such as input/output paths, column names, filters, and other parameters — in external YAML, JSON, or TOML files. This approach separates the logic from the configuration, making it easier to adjust parameters for different environments or datasets without modifying the code.
import yaml
with open('config.yaml') as file:
config = yaml.safe_load(file)
Scalability
Scalability refers to the capacity of an ETL pipeline to handle increasing volumes of data or a growing number of data sources. Non-scalable ETL pipelines encounter challenges when processing large datasets, resulting in higher computing costs and longer processing times. This issue is particularly critical in scenarios where significant data growth is anticipated in the future.
What can we do to prevent this?
- Filter as Early as Possible: Apply filters at the earliest stages of the pipeline to minimize the volume of data processed in subsequent steps.
- Avoid Unnecessary Transformations: Steer clear of unnecessary transformations, such as sorting, which can add overhead and slow down processing.
- Use Incremental Loads: Reloading an entire dataset each time can be extremely inefficient and costly as data volumes grow. Instead, focus on transforming only the new or changed data.
- Optimize Data Formats: Choose efficient data formats for loading and output. For columnar data, consider using Parquet files, which optimize storage and processing time. For semi-structured data, use Avro or JSON with compression.
- Minimize Joins: Joins involving large datasets can be costly in terms of performance. Consider denormalizing tables to reduce the need for complex joins.
- Monitoring: Implement monitoring to estimate the time required for the ETL process with different data volumes. By measuring the duration for executing the ETL process with various row counts, you can better understand performance. Consider encapsulating your ETL process in a function for easier measurement.
To illustrate how we can monitor the data, I will use example data that I previously featured in my blog about Efficient Testing of ETL Pipelines with Python. In this section, I won’t delve deeply into the details of this example. If you’re interested in a more comprehensive explanation, please refer to the other blog.
We will begin by copying our ETL pipeline and encapsulating it within a function:
import pandas as pd
def run_etl_pipeline(order_df, customer_df):
# 1.2 Adjust column (convert 'order_date' to datetime)
df1_change_datatype_orderdate = order_df.assign(order_date=pd.to_datetime(order_df['order_date']))
# 1.3 Add new column 'year'
df1_add_column_year = df1_change_datatype_orderdate.assign(year=lambda x: x['order_date'].dt.year)
# 1.4 Filter year 2023
df1_filtered_year = df1_add_column_year[df1_add_column_year['year'] == 2023]
# 1.5 Aggregate data
df1_aggregated = df1_filtered_year.groupby(['customer_id']).agg(
total_price=('total_price', 'sum'),
unique_order=('order_id', 'nunique')
).reset_index()
# 1.6 Merge the aggregated data with customer data
merged_df1_df2 = pd.merge(df1_aggregated, customer_df, left_on='customer_id', right_on='id')
return merged_df1_df2
Please note that we won’t be reading in the data within the function. Instead, the input DataFrames will be provided as parameters.
# Load data externally
import time
import pandas as pd
order_df = pd.read_csv(r"\order_table.csv")
customer_df = pd.read_csv(r"\customer_table.csv")
sample_size=[]
duration_list =[]
for i in range(0,1000001,10000):
start_time=time.time()
order_df_sample = order_df.sample(n=i,replace=True)
run_etl_pipeline(order_df_sample, customer_df)
end_time = time.time()
duration = end_time - start_time
sample_size+=[i]
duration_list+=[duration]
scalability_tracker = pd.DataFrame({'Sample':sample_size,'Duration':duration_list})
Next, we will loop from 10,000 to 1,000,000 steps through one of the DataFrames. During this process, we will randomly select 10,000 rows from the DataFrame, allowing for the possibility of selecting the same rows multiple times. We will measure the time taken before execution and after execution using our simulated data. In the end, this will provide us with a scalability tracker that we can also visualize.
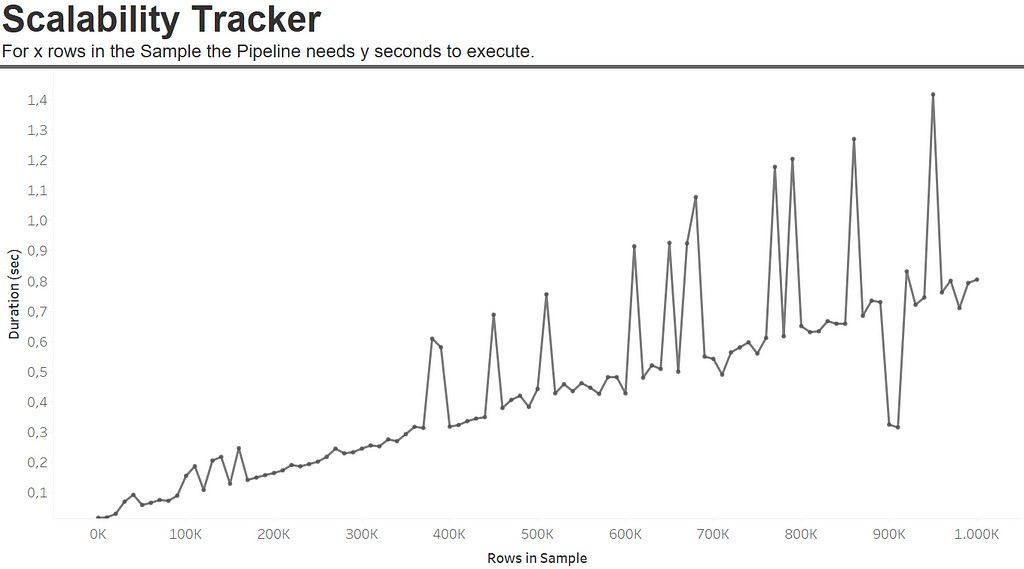
In this example, transforming 1 million rows in the order table takes approximately 0.8 seconds. Even more interestingly, we observe a linear relationship in the transformation times. This allows us to easily estimate the time required for the data we expect to receive in the upcoming month, enabling us to proactively prevent any data delivery delays.
Maintainability
Maintainability refers to how easily an ETL pipeline can be updated, modified, or fixed over time. In a rapidly changing world, where data volumes are increasing and data teams are expanding, having maintainable workflows is crucial. Such workflows enable new team members to understand the process more easily and help maintain an overall overview of the pipeline. Additionally, maintainable workflows are much faster to fix when it comes to error handling and are easier to update as requirements evolve.
- Documentation: Write clear and concise documentation for your ETL pipeline. This should include instructions on how to run the pipeline, configurations, dependencies, expected inputs/outputs, and common troubleshooting steps.
- Testing: Implementing tests can save you significant time in finding and fixing errors. There are various testing strategies you can use. I highly recommend checking out my blog on Efficient Testing of ETL Pipelines with Python — you can thank me later! :)
- Use Data Lineage: Maintaining an overview of your ETL pipelines and their interdependencies can be helpful in localizing issues throughout your workflow.
- Define the purpose: When evaluating a new ETL pipeline, one of the first questions you should ask is: Why? Understand the purpose of the pipeline and why it needs to exist. This definition not only helps other team members better understand your pipeline but also enables quicker error resolution since the goal and objectives are clear.
These are just a few key tips for maintaining ETL workflows, but I know there are many more strategies out there. For me, these are the most important practices to help manage my workflows effectively.
How do you keep your workflows maintainable? I’m really curious to hear your thoughts, so please share your tips in the comments!
Use Cases
Use Case 1: Data Migration for a One-Time Acquisition
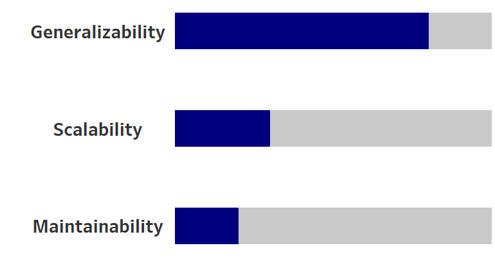
You’re tasked with migrating data between two companies after an acquisition. You need to integrate data from the acquired company’s systems into your own for financial reporting, customer records, and inventory management. This is a one-time project where the key challenge is that the acquired company’s data has a completely different structure, requiring flexible handling of different data formats and schemas.
The acquired company might use various systems, such as Salesforce, QuickBooks, and proprietary databases. A generalizable ETL pipeline must be adaptable to extract data from these disparate systems, regardless of their format or structure. Since the integration is a one-time effort, the system does not need to be highly maintainable. You won’t need to revisit or update the pipeline frequently, making maintainability a lower priority. Scalability is not a concern because the data migration involves a finite, fixed amount of data from the acquired company. The system does not need to handle increasing data volumes over time, unlike a regular operational ETL process.
Use Case 2: Real-Time Data Processing for E-Commerce Sales
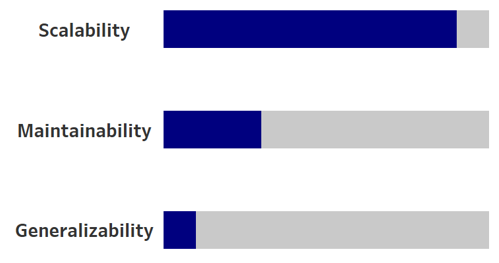
Imagine an e-commerce platform that experiences rapid growth in user traffic and transaction volumes, especially during peak seasons like Black Friday or holiday sales. The platform needs to process and analyze real-time sales data to generate insights, optimize inventory, and provide personalized recommendations to users.
The platform expects millions of transactions during peak shopping periods. The ETL pipeline must handle this substantial influx of data without performance degradation. As the business grows, the volume of incoming data will increase, necessitating a scalable solution that can easily adapt to this growth. The system must accommodate an expanding range of data sources, including new sales channels and payment processors. The ETL pipeline is tailored specifically for the e-commerce sales environment, so it may not need to generalize to other data sources or use cases outside of this context. During peak seasons, the priority is on maximizing throughput and minimizing latency. Long-term maintainability and the ability to handle future projects may take a backseat to ensuring that the current pipeline can scale effectively.
Conclusion
In conclusion, designing effective ETL pipelines that are generalizable, scalable, and maintainable is essential for modern data workflows. By focusing on these three pillars, data engineers can create pipelines that not only meet current requirements but also adapt to future changes and growth.
As data ecosystems evolve, adopting these principles will empower organizations to leverage their data effectively, driving better insights and decision-making. I encourage you to reflect on your own ETL practices and consider how you can incorporate these strategies into your workflows. Share your experiences and tips in the comments below!
Thank you for joining me on this journey through ETL best practices! If you enjoyed the insights shared or found them useful, I’d greatly appreciate your support. A simple clap or a follow would mean the world to me! Your engagement motivates me to continue creating content that helps us all navigate the data landscape together.
Alteryx Community, 2023. Implementing Workflow Strategy:nj Generalizability. Alteryx Community. Available at: https://community.alteryx.com/t5/Engine-Works/Implementing-Workflow-Strategy-Generalizability/ba-p/1296109 [Accessed 18 October 2024].
Alteryx Community, 2023. Implementing Workflow Strategy: Scalability. Alteryx Community. Available at: https://community.alteryx.com/t5/Engine-Works/Implementing-Workflow-Strategy-Scalability/ba-p/1297766 [Accessed 18 October 2024].
ETL Pipelines in Python: Best Practices and Techniques was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/Xfw57lU
via IFTTT


