
Running the STORM AI research system with your local documents
Running the STORM AI Research System with Your Local Documents
AI assisted research using FEMA disaster response documents
TL;DR
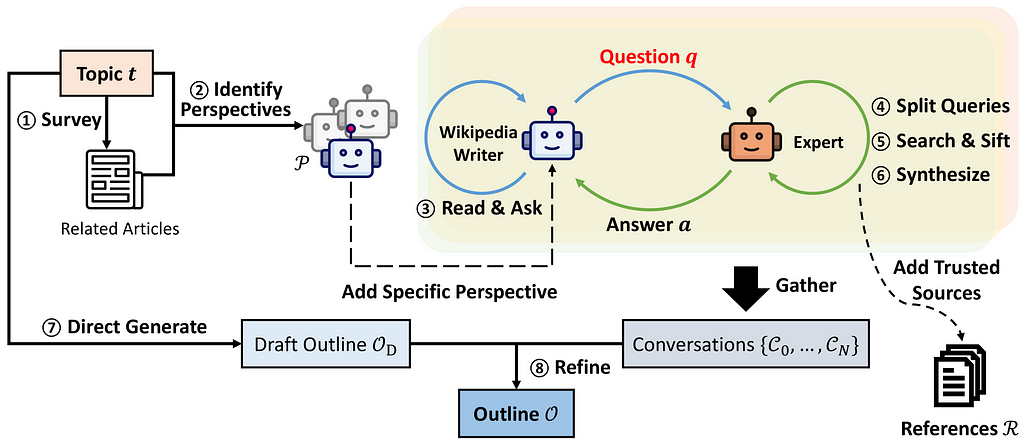
The use of LLM agents is becoming more common for tackling multi-step long-context research tasks where traditional RAG direct prompting methods can sometimes struggle. In this article, we will explore a new and promising technique developed by Stanford called Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking (STORM), which uses LLM agents to simulate ‘Perspective-guided conversations’ to reach complex research goals and generate rich research articles that can be used by humans in their pre-writing research. STORM was initially developed to gather information from web sources but also supports searching a local document vector store. In this article we will see how to implement STORM for AI-supported research on local PDFs, using US FEMA disaster preparedness and assistance documentation.
It’s been amazing to watch how using LLMs for knowledge retrieval has progressed in a relatively short period of time. Since the first paper on Retrieval Augmented Generation (RAG) in 2020, we have seen the ecosystem grow to include a cornucopia of available techniques. One of the more advanced is agentic RAG where LLM agents iterate and refine document retrieval in order to solve more complex research tasks. It’s similar to how a human might carry out research, exploring a range of different search queries to build a better idea of the context, sometimes discussing the topic with other humans, and synthesizing everything into a final result. Single-turn RAG, even employing techniques such as query expansion and reranking, can struggle with more complex multi-hop research tasks like this.
There are quite a few patterns for knowledge retrieval using agent frameworks such as Autogen, CrewAI, and LangGraph as well as specific AI research assistants such as GPT Researcher. In this article, we will look at an LLM-powered research writing system from Stanford University, called Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking (STORM).
STORM AI research writing system
STORM applies a clever technique where LLM agents simulate ‘Perspective-guided conversations’ to reach a research goal as well as extend ‘outline-driven RAG’ for richer article generation.
Configured to generate Wikipedia-style articles, it was tested with a cohort of 10 experienced Wikipedia editors.
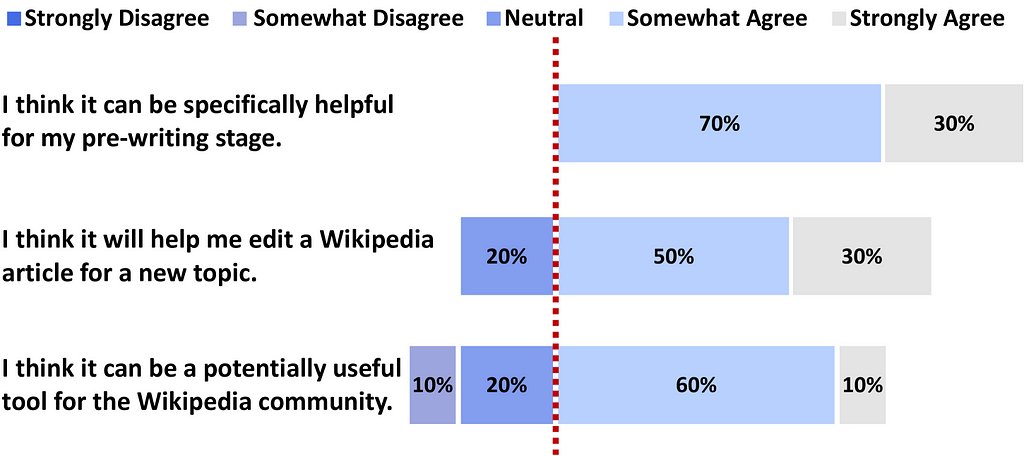
Reception on the whole was positive, 70% of the editors felt that it would be a useful tool in their pre-writing stage when researching a topic. I hope in the future surveys could include more than 10 editors, but it should be noted that authors also benchmarked traditional article generation methods using FreshWiki, a dataset of recent high-quality Wikipedia articles, where STORM was found to outperform previous techniques.
STORM is open source and available as a Python package with additional implementations using frameworks such as LangGraph. More recently STORM has been enhanced to support human-AI collaborative knowledge curation called Co-STORM, putting a human right in the center of the AI-assisted research loop.
Though it significantly outperforms baseline methods in both automatic and human evaluations, there are some caveats that the authors acknowledge. It isn’t yet multimodal, doesn’t produce experienced human-quality content — it isn’t positioned yet for this I feel, being more targeted for pre-writing research than final articles — and there are some nuances around references that require some future work. That said, if you have a deep research task, it’s worth checking out.
You can try out STORM online — it’s fun! — configured to perform research using information on the web.
But what about running STORM with your own data?
Many organizations will want to use AI research tools with their own internal data. The STORM authors have done a nice job of documenting various approaches of using STORM with different LLM providers and a local vector database, which means it is possible to run STORM on your own documents.
So let’s try this out!
Setup and code
You can find the code for this article here, which includes environment setup instructions and how to collate some sample documents for this demo.
FEMA disaster preparedness and assistance documentation
We will use 34 PDF documents to help people prepare for and respond to disasters, as created by the United States Federal Emergency Management Agency (FEMA). These documents perhaps aren’t typically what people may want to use for writing deep research articles, but I’m interested in seeing how AI can help people prepare for disasters.
…. and I have the code already written for processing FEMA reports from some earlier blog posts, which I’ve included in the linked repo above. 😊
Parsing and Chunking
Once we have our documents, we need to split them into smaller documents so that STORM can search for specific topics within the corpus. Given STORM is originally aimed at generating Wikipedia-style articles, I opted to try two approaches, (i) Simply splitting the documents into sub-documents by page using LangChain’s PyPDFLoader, to create a crude simulation of a Wikipedia page which includes several sub-topics. Many FEMA PDFs are single-page documents that don’t look too dissimilar to Wikipedia articles; (ii) Further chunking the documents into smaller sections, more likely to cover a discrete sub-topic.
These are of course very basic approaches to parsing, but I wanted to see how results varied depending on the two techniques. Any serious use of STORM on local documents should invest in all the usual fun around paring optimization.
def parse_pdfs():
"""
Parses all PDF files in the specified directory and loads their content.
This function iterates through all files in the directory specified by PDF_DIR,
checks if they have a .pdf extension, and loads their content using PyPDFLoader.
The loaded content from each PDF is appended to a list which is then returned.
Returns:
list: A list containing the content of all loaded PDF documents.
"""
docs = []
pdfs = os.listdir(PDF_DIR)
print(f"We have {len(pdfs)} pdfs")
for pdf_file in pdfs:
if not pdf_file.endswith(".pdf"):
continue
print(f"Loading PDF: {pdf_file}")
file_path = f"{PDF_DIR}/{pdf_file}"
loader = PyPDFLoader(file_path)
docs = docs + loader.load()
print(f"Loaded {len(docs)} documents")
return docs
docs = parse_pdfs()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(docs)
Metadata enrichment
STORM’s example documentation requires that documents have metadata fields ‘URL’, ‘title’, and ‘description’, where ‘URL’ should be unique. Since we are splitting up PDF documents, we don’t have titles and descriptions of individual pages and chunks, so I opted to generate these with a simple LLM call.
For URLs, we have them for individual PDF pages, but for chunks within a page. Sophisticated knowledge retrieval systems can have metadata generated by layout detection models so the text chunk area can be highlighted in the corresponding PDF, but for this demo, I simply added an ‘_id’ query parameter the URL which does nothing but ensure they are unique for chunks.
def summarize_text(text, prompt):
"""
Generate a summary of some text based on the user's prompt
Args:
text (str) - the text to analyze
prompt (str) - prompt instruction on how to summarize the text, eg 'generate a title'
Returns:
summary (text) - LLM-generated summary
"""
messages = [
(
"system",
"You are an assistant that gives very brief single sentence description of text.",
),
("human", f"{prompt} :: \n\n {text}"),
]
ai_msg = llm.invoke(messages)
summary = ai_msg.content
return summary
def enrich_metadata(docs):
"""
Uses an LLM to populate 'title' and 'description' for text chunks
Args:
docs (list) - list of LangChain documents
Returns:
docs (list) - list of LangChain documents with metadata fields populated
"""
new_docs = []
for doc in docs:
# pdf name is last part of doc.metadata['source']
pdf_name = doc.metadata["source"].split("/")[-1]
# Find row in df where pdf_name is in URL
row = df[df["Document"].str.contains(pdf_name)]
page = doc.metadata["page"] + 1
url = f"{row['Document'].values[0]}?id={str(uuid4())}#page={page}"
# We'll use an LLM to generate a summary and title of the text, used by STORM
# This is just for the demo, proper application would have better metadata
summary = summarize_text(doc.page_content, prompt="Please describe this text:")
title = summarize_text(
doc.page_content, prompt="Please generate a 5 word title for this text:"
)
doc.metadata["description"] = summary
doc.metadata["title"] = title
doc.metadata["url"] = url
doc.metadata["content"] = doc.page_content
# print(json.dumps(doc.metadata, indent=2))
new_docs.append(doc)
print(f"There are {len(docs)} docs")
return new_docs
docs = enrich_metadata(docs)
chunks = enrich_metadata(chunks)
Building vector databases
STORM already supports the Qdrant vector store. I like to use frameworks such as LangChain and Llama Index where possible to make it easier to change providers down the road, so I opted to use LangChain to build a local Qdrant vector database persisted to the local file system rather than STORM’s automatic vector database management. I felt this offers more control and is more recognizable to those who already have pipelines for populating document vector stores.
def build_vector_store(doc_type, docs):
"""
Givena list of LangChain docs, will embed and create a file-system Qdrant vector database.
The folder includes doc_type in its name to avoid overwriting.
Args:
doc_type (str) - String to indicate level of document split, eg 'pages',
'chunks'. Used to name the database save folder
docs (list) - List of langchain documents to embed and store in vector database
Returns:
Nothing returned by function, but db saved to f"{DB_DIR}_{doc_type}".
"""
print(f"There are {len(docs)} docs")
save_dir = f"{DB_DIR}_{doc_type}"
print(f"Saving vectors to directory {save_dir}")
client = QdrantClient(path=save_dir)
client.create_collection(
collection_name=DB_COLLECTION_NAME,
vectors_config=VectorParams(size=num_vectors, distance=Distance.COSINE),
)
vector_store = QdrantVectorStore(
client=client,
collection_name=DB_COLLECTION_NAME,
embedding=embeddings,
)
uuids = [str(uuid4()) for _ in range(len(docs))]
vector_store.add_documents(documents=docs, ids=uuids)
build_vector_store("pages", docs)
build_vector_store("chunks", docs)
Running STORM
The STORM repo has some great examples of different search engines and LLMs, as well as using a Qdrant vector store. I decided to combine various features from these, plus some extra post-processing as follows:
- Added ability to run with OpenAI or Ollama
- Added support for passing in the vector database directory
- Added a function to parse the references metadata file to add references to the generated polished article. STORM generated these references in a JSON file but didn’t add them to the output article automatically. I’m not sure if this was due to some setting I missed, but references are key to evaluating any AI research technique, so I added this custom post-processing step.
- Finally, I noticed that open models have more guidance in templates and personas due to their following instructions less accurately than commercial models. I liked the transparency of these controls and left them in for OpenAI so that I could adjust in future work.
Here is everything (see repo notebook for full code) …
def set_instructions(runner):
"""
Adjusts templates and personas for the STORM AI Research algorithm.
Args:
runner - STORM runner object
Returns:
runner - STORM runner object with extra prompting
"""
# Open LMs are generally weaker in following output format.
# One way for mitigation is to add one-shot example to the prompt to exemplify the desired output format.
# For example, we can add the following examples to the two prompts used in StormPersonaGenerator.
# Note that the example should be an object of dspy.Example with fields matching the InputField
# and OutputField in the prompt (i.e., dspy.Signature).
find_related_topic_example = Example(
topic="Knowledge Curation",
related_topics="https://en.wikipedia.org/wiki/Knowledge_management\n"
"https://en.wikipedia.org/wiki/Information_science\n"
"https://en.wikipedia.org/wiki/Library_science\n",
)
gen_persona_example = Example(
topic="Knowledge Curation",
examples="Title: Knowledge management\n"
"Table of Contents: History\nResearch\n Dimensions\n Strategies\n Motivations\nKM technologies"
"\nKnowledge barriers\nKnowledge retention\nKnowledge audit\nKnowledge protection\n"
" Knowledge protection methods\n Formal methods\n Informal methods\n"
" Balancing knowledge protection and knowledge sharing\n Knowledge protection risks",
personas="1. Historian of Knowledge Systems: This editor will focus on the history and evolution of knowledge curation. They will provide context on how knowledge curation has changed over time and its impact on modern practices.\n"
"2. Information Science Professional: With insights from 'Information science', this editor will explore the foundational theories, definitions, and philosophy that underpin knowledge curation\n"
"3. Digital Librarian: This editor will delve into the specifics of how digital libraries operate, including software, metadata, digital preservation.\n"
"4. Technical expert: This editor will focus on the technical aspects of knowledge curation, such as common features of content management systems.\n"
"5. Museum Curator: The museum curator will contribute expertise on the curation of physical items and the transition of these practices into the digital realm.",
)
runner.storm_knowledge_curation_module.persona_generator.create_writer_with_persona.find_related_topic.demos = [
find_related_topic_example
]
runner.storm_knowledge_curation_module.persona_generator.create_writer_with_persona.gen_persona.demos = [
gen_persona_example
]
# A trade-off of adding one-shot example is that it will increase the input length of the prompt. Also, some
# examples may be very long (e.g., an example for writing a section based on the given information), which may
# confuse the model. For these cases, you can create a pseudo-example that is short and easy to understand to steer
# the model's output format.
# For example, we can add the following pseudo-examples to the prompt used in WritePageOutlineFromConv and
# ConvToSection.
write_page_outline_example = Example(
topic="Example Topic",
conv="Wikipedia Writer: ...\nExpert: ...\nWikipedia Writer: ...\nExpert: ...",
old_outline="# Section 1\n## Subsection 1\n## Subsection 2\n"
"# Section 2\n## Subsection 1\n## Subsection 2\n"
"# Section 3",
outline="# New Section 1\n## New Subsection 1\n## New Subsection 2\n"
"# New Section 2\n"
"# New Section 3\n## New Subsection 1\n## New Subsection 2\n## New Subsection 3",
)
runner.storm_outline_generation_module.write_outline.write_page_outline.demos = [
write_page_outline_example
]
write_section_example = Example(
info="[1]\nInformation in document 1\n[2]\nInformation in document 2\n[3]\nInformation in document 3",
topic="Example Topic",
section="Example Section",
output="# Example Topic\n## Subsection 1\n"
"This is an example sentence [1]. This is another example sentence [2][3].\n"
"## Subsection 2\nThis is one more example sentence [1].",
)
runner.storm_article_generation.section_gen.write_section.demos = [
write_section_example
]
return runner
def latest_dir(parent_folder):
"""
Find the most recent folder (by modified date) in the specified parent folder.
Args:
parent_folder (str): The path to the parent folder where the search for the most recent folder will be conducted. Defaults to f"{DATA_DIR}/storm_output".
Returns:
str: The path to the most recently modified folder within the parent folder.
"""
# Find most recent folder (by modified date) in DATA_DIR/storm_data
# TODO, find out how exactly storm passes back its output directory to avoid this hack
folders = [f.path for f in os.scandir(parent_folder) if f.is_dir()]
folder = max(folders, key=os.path.getmtime)
return folder
def generate_footnotes(folder):
"""
Generates footnotes from a JSON file containing URL information.
Args:
folder (str): The directory path where the 'url_to_info.json' file is located.
Returns:
str: A formatted string containing footnotes with URLs and their corresponding titles.
"""
file = f"{folder}/url_to_info.json"
with open(file) as f:
data = json.load(f)
refs = {}
for rec in data["url_to_unified_index"]:
val = data["url_to_unified_index"][rec]
title = data["url_to_info"][rec]["title"].replace('"', "")
refs[val] = f"- {val} [{title}]({rec})"
keys = list(refs.keys())
keys.sort()
footer = ""
for key in keys:
footer += f"{refs[key]}\n"
return footer, refs
def generate_markdown_article(output_dir):
"""
Generates a markdown article by reading a text file, appending footnotes,
and saving the result as a markdown file.
The function performs the following steps:
1. Retrieves the latest directory using the `latest_dir` function.
2. Generates footnotes for the article using the `generate_footnotes` function.
3. Reads the content of a text file named 'storm_gen_article_polished.txt'
located in the latest directory.
4. Appends the generated footnotes to the end of the article content.
5. Writes the modified content to a new markdown file named
STORM_OUTPUT_MARKDOWN_ARTICLE in the same directory.
Args:
output_dir (str) - The directory where the STORM output is stored.
"""
folder = latest_dir(output_dir)
footnotes, refs = generate_footnotes(folder)
with open(f"{folder}/storm_gen_article_polished.txt") as f:
text = f.read()
# Update text references like [10] to link to URLs
for ref in refs:
print(f"Ref: {ref}, Ref_num: {refs[ref]}")
url = refs[ref].split("(")[1].split(")")[0]
text = text.replace(f"[{ref}]", f"\[[{ref}]({url})\]")
text += f"\n\n## References\n\n{footnotes}"
with open(f"{folder}/{STORM_OUTPUT_MARKDOWN_ARTICLE}", "w") as f:
f.write(text)
def run_storm(topic, model_type, db_dir):
"""
This function runs the STORM AI Research algorithm using data
in a QDrant local database.
Args:
topic (str) - The research topic to generate the article for
model_type (str) - One of 'openai' and 'ollama' to control LLM used
db_dir (str) - Directory where the QDrant vector database is
"""
if model_type not in ["openai", "ollama"]:
print("Unsupported model_type")
sys.exit()
# Clear lock so can be read
if os.path.exists(f"{db_dir}/.lock"):
print(f"Removing lock file {db_dir}/.lock")
os.remove(f"{db_dir}/.lock")
print(f"Loading Qdrant vector store from {db_dir}")
engine_lm_configs = STORMWikiLMConfigs()
if model_type == "openai":
print("Using OpenAI models")
# Initialize the language model configurations
openai_kwargs = {
"api_key": os.getenv("OPENAI_API_KEY"),
"temperature": 1.0,
"top_p": 0.9,
}
ModelClass = (
OpenAIModel
if os.getenv("OPENAI_API_TYPE") == "openai"
else AzureOpenAIModel
)
# If you are using Azure service, make sure the model name matches your own deployed model name.
# The default name here is only used for demonstration and may not match your case.
gpt_35_model_name = (
"gpt-4o-mini"
if os.getenv("OPENAI_API_TYPE") == "openai"
else "gpt-35-turbo"
)
gpt_4_model_name = "gpt-4o"
if os.getenv("OPENAI_API_TYPE") == "azure":
openai_kwargs["api_base"] = os.getenv("AZURE_API_BASE")
openai_kwargs["api_version"] = os.getenv("AZURE_API_VERSION")
# STORM is a LM system so different components can be powered by different models.
# For a good balance between cost and quality, you can choose a cheaper/faster model for conv_simulator_lm
# which is used to split queries, synthesize answers in the conversation. We recommend using stronger models
# for outline_gen_lm which is responsible for organizing the collected information, and article_gen_lm
# which is responsible for generating sections with citations.
conv_simulator_lm = ModelClass(
model=gpt_35_model_name, max_tokens=10000, **openai_kwargs
)
question_asker_lm = ModelClass(
model=gpt_35_model_name, max_tokens=10000, **openai_kwargs
)
outline_gen_lm = ModelClass(
model=gpt_4_model_name, max_tokens=10000, **openai_kwargs
)
article_gen_lm = ModelClass(
model=gpt_4_model_name, max_tokens=10000, **openai_kwargs
)
article_polish_lm = ModelClass(
model=gpt_4_model_name, max_tokens=10000, **openai_kwargs
)
elif model_type == "ollama":
print("Using Ollama models")
ollama_kwargs = {
# "model": "llama3.2:3b",
"model": "llama3.1:latest",
# "model": "qwen2.5:14b",
"port": "11434",
"url": "http://localhost",
"stop": (
"\n\n---",
), # dspy uses "\n\n---" to separate examples. Open models sometimes generate this.
}
conv_simulator_lm = OllamaClient(max_tokens=500, **ollama_kwargs)
question_asker_lm = OllamaClient(max_tokens=500, **ollama_kwargs)
outline_gen_lm = OllamaClient(max_tokens=400, **ollama_kwargs)
article_gen_lm = OllamaClient(max_tokens=700, **ollama_kwargs)
article_polish_lm = OllamaClient(max_tokens=4000, **ollama_kwargs)
engine_lm_configs.set_conv_simulator_lm(conv_simulator_lm)
engine_lm_configs.set_question_asker_lm(question_asker_lm)
engine_lm_configs.set_outline_gen_lm(outline_gen_lm)
engine_lm_configs.set_article_gen_lm(article_gen_lm)
engine_lm_configs.set_article_polish_lm(article_polish_lm)
max_conv_turn = 4
max_perspective = 3
search_top_k = 10
max_thread_num = 1
device = "cpu"
vector_db_mode = "offline"
do_research = True
do_generate_outline = True
do_generate_article = True
do_polish_article = True
# Initialize the engine arguments
output_dir=f"{STORM_OUTPUT_DIR}/{db_dir.split('db_')[1]}"
print(f"Output directory: {output_dir}")
engine_args = STORMWikiRunnerArguments(
output_dir=output_dir,
max_conv_turn=max_conv_turn,
max_perspective=max_perspective,
search_top_k=search_top_k,
max_thread_num=max_thread_num,
)
# Setup VectorRM to retrieve information from your own data
rm = VectorRM(
collection_name=DB_COLLECTION_NAME,
embedding_model=EMBEDDING_MODEL,
device=device,
k=search_top_k,
)
# initialize the vector store, either online (store the db on Qdrant server) or offline (store the db locally):
if vector_db_mode == "offline":
rm.init_offline_vector_db(vector_store_path=db_dir)
# Initialize the STORM Wiki Runner
runner = STORMWikiRunner(engine_args, engine_lm_configs, rm)
# Set instructions for the STORM AI Research algorithm
runner = set_instructions(runner)
# run the pipeline
runner.run(
topic=topic,
do_research=do_research,
do_generate_outline=do_generate_outline,
do_generate_article=do_generate_article,
do_polish_article=do_polish_article,
)
runner.post_run()
runner.summary()
generate_markdown_article(output_dir)
We’re ready to run STORM!
For the research topic, I picked something that would be challenging to answer with a typical RAG system and which wasn’t well covered in the PDF data so we can see how well attribution works …
“Compare the financial impact of different types of disasters and how those impact communities”
Running this for both databases …
query = "Compare the financial impact of different types of disasters and how those impact communities"
for doc_type in ["pages", "chunks"]:
db_dir = f"{DB_DIR}_{doc_type}"
run_storm(query=query, model_type="openai", db_dir=db_dir)
Using OpenAI, the process took about 6 minutes on my Macbook pro M2 (16GB memory). I would note that other simpler queries where we have more supporting content in the underlying documents were much faster (< 30 seconds in some cases).
STORM results
STORM generates a set of output files …
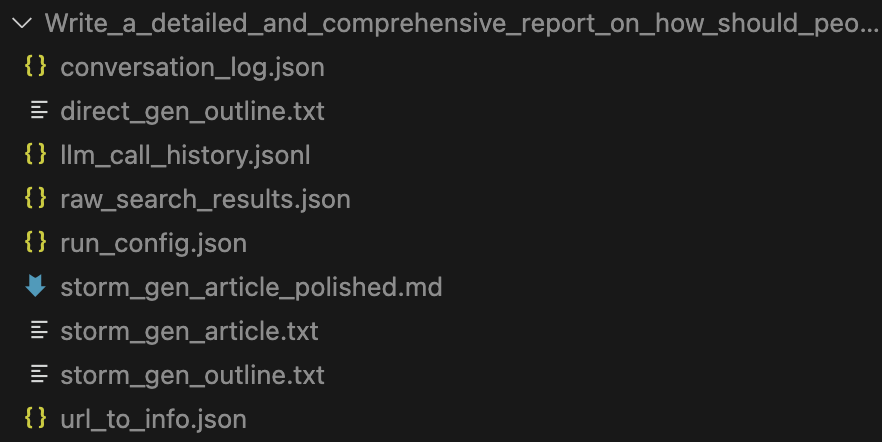
It’s interesting to review the conversation_log.json and llm_call_history.json to see the perspective-guided conversations component.
For our research topic …
“Compare the financial impact of different types of disasters and how those impact communities”
You can find the generated articles here …
- STORM generated article — using text split by page
- STORM generated article — using text further chunked using RecursiveTextSplitter
Some quick observations
This demo doesn’t get into a formal evaluation — which can be more involved than single-hop RAG systems — but here are some subjective observations that may or may not be useful …
- Parsing by page or by smaller chunks produces reasonable pre-reading reports that a human could use for researching areas related to the financial impact of disasters
- Both paring approaches provided citations throughout, but using smaller chunks seemed to result in fewer. See for example the Summary sections in both of the above articles. The more references to ground the analysis, the better!
- Parsing by smaller chunks seemed to sometimes create citations that were not relevant, one of the citation challenges mentioned in the STORM paper. See for example citation for source ‘10’ in the summary section, which doesn’t correspond with the reference sentence.
- Overall, as expected for an algorithm developed on Wiki articles, splitting text by PDF seemed to produce a more cohesive and grounded article (to me!)
Even though the input research topic wasn’t covered in great depth in the underlying documents, the generated report was a great starting point for further human analysis
Future Work
We didn’t get into Co-Storm in this article, which brings a human into the loop. This seems a great direction for AI-empowered research and something I am investigating.
Future work could also look at adjusting the system prompts and personas to the business case. Currently, those prompts are targeted for a Wikipedia-like process …

Another possible direction is to extend STORM’s connectors beyond Qdrant, for example, to include other vector stores, or better still, generic support for Langchain and llama index vector stores. The authors encourage this type of thing, a PR involving this file may be in my future.
Running STORM without an internet connection would be an amazing thing, as it opens up possibilities for AI assistance in the field. As you can see from the demo code, I added the ability to run STORM with Ollama locally hosted models, but the token throughput rate was too low for the LLM agent discussion phase, so the system didn’t complete on my laptop with small quantized models. A topic for a future blog post perhaps!
Finally, though the online User Interface is very nice, the demo UI that comes with the repo is very basic and not something that could be used in production. Perhaps the Standford team might release the advanced interface — maybe it is already somewhere? — if not then work would be needed here.
Conclusions
This is a quick demo to hopefully help people get started with using STORM on their own documents. I haven’t gone into systematic evaluation, something that would obviously need to be done if using STORM in a live environment. That said, I was impressed at how it seems to be able to get a relatively nuanced research topic and generate well-cited pre-writing research content that would help me in my own research.
References
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Lewis et al., 2020
Retrieval-Augmented Generation for Large Language Models: A Survey, Yunfan et al., 2024
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models, Shao et al., 2024
Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations, Jiang et al., 2024
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries, Tang et al., 2024
You can find the code for this article here
Please like this article if inclined and I’d be super delighted if you followed me! You can find more articles here or connect on LinkedIn.
Running the STORM AI research system with your local documents was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/zrkldMH
via IFTTT


