
The Ultimate Guide to RAGs — Each Component Dissected
The Ultimate Guide to RAGs — Each Component Dissected
A visual tour of what it takes to build CHAD-level LLM pipelines
If you have worked with Large Language Models, there is a great chance that you have at least heard the term RAG — Retrieval Augmented Generation. The idea of RAGs are pretty simple — suppose you want to ask a question to a LLM, instead of just relying on the LLM’s pre-trained knowledge, you first retrieve relevant information from an external knowledge base. This retrieved information is then provided to the LLM along with the question, allowing it to generate a more informed and up-to-date response.
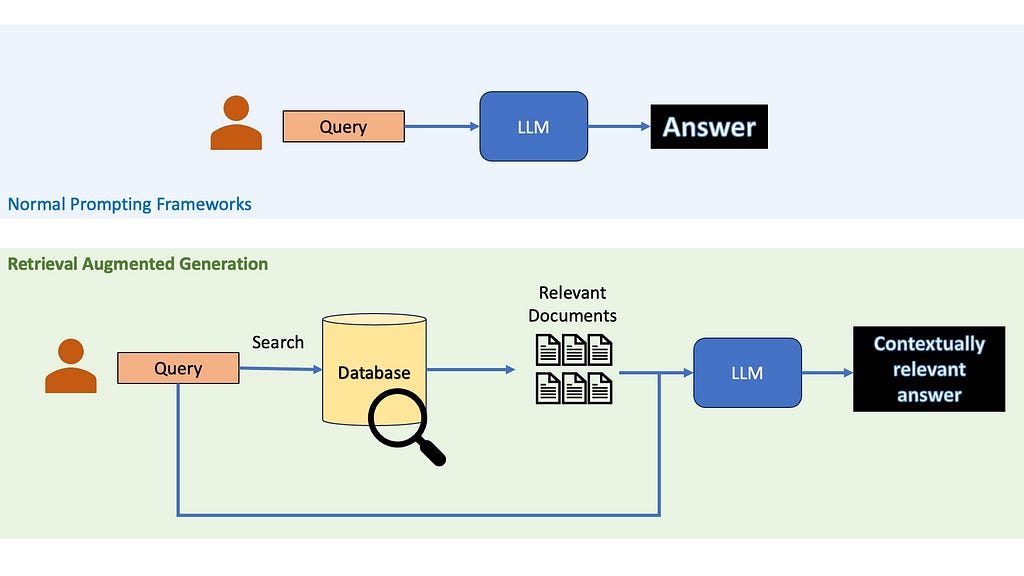
So, why use Retrieval Augmented Generation?
When providing accurate and up-to-date information is key, you cannot rely on the LLM’s inbuilt knowledge. RAGs are a cheap practical way to use LLMs to generate content about recent topics or niche topics without needing to finetune them on your own and burn away your life’s savings. Even when LLMs internal knowledge may be enough to answer questions, it might be a good idea to use RAGs anyway, since recent studies have shown that they could help reduce LLMs hallucinations.
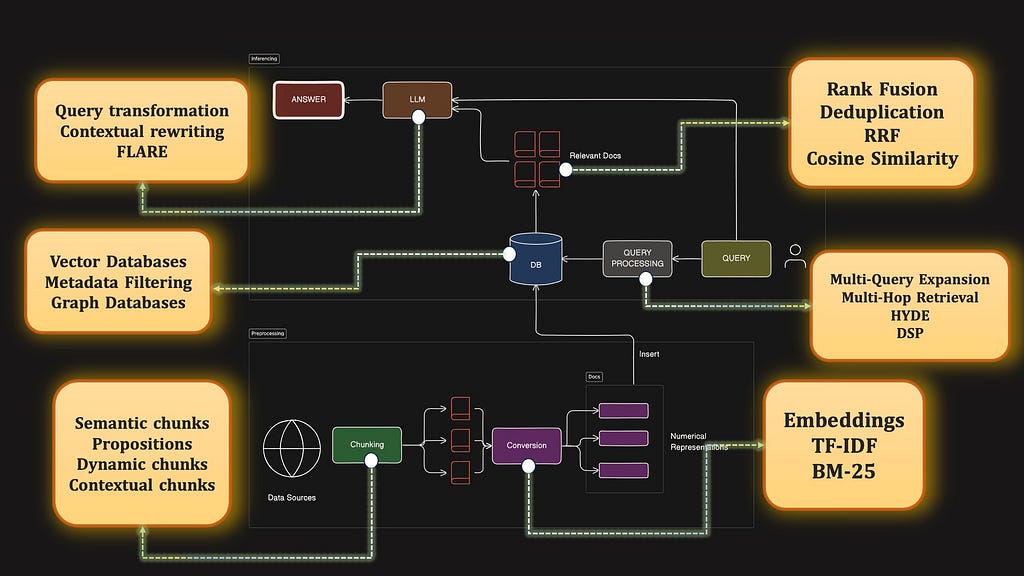
The different components of a bare-bones RAG
Before we dive into the advanced portion of this article, let’s review the basics. Generally RAGs consist of two pipelines — preprocessing and inferencing.
Inferencing is all about using data from your existing database to answer questions from a user query. Preprocessing is the process of setting up the database in the correct way so that retrieval is done correctly later on.
Here is a diagramatic look into the entire basic barebones RAG pipeline.
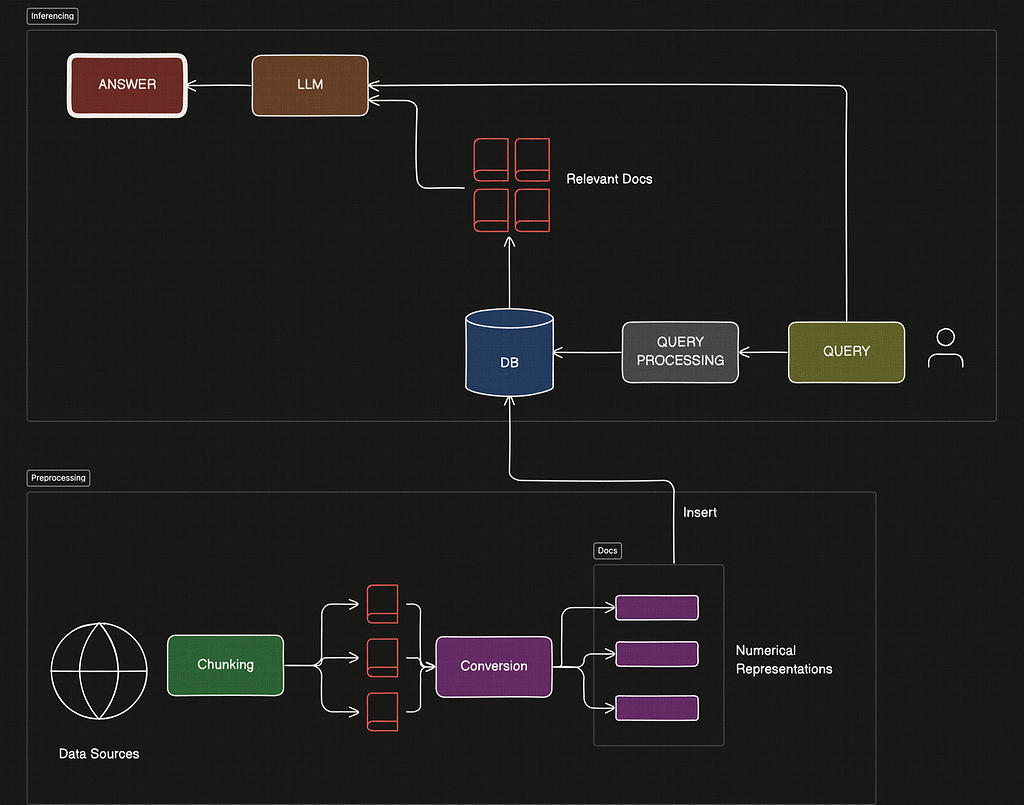
The Indexing or Preprocessing Steps
This is the offline preprocessing stage, where we would set up our database.
- Identify Data Source: Choose a relevant data source based on the application, such as Wikipedia, books, or manuals. Since this is domain dependent, I am going to skip over this step in this article. Go choose any data you want to use, knock yourself out!
- Chunking the Data: Break down the dataset into smaller, manageable documents or chunks.
- Convert to Searchable Format: Transform each chunk into a numerical vector or similar searchable representation.
- Insert into Database: Store these searchable chunks in a custom database, though external databases or search engines could also be used.
The Inferencing Steps
During the Query Inferencing stage, the following components stand out.
- Query Processing: A method to convert the user’s query into a format suitable for search.
- Retrieval/Search Strategy: A similarity search mechanism to retrieve the most relevant documents.
- Post-Retrieval Answer Generation: Use retrieved documents as context to generate the answer with an LLM.
Great — so we identified several key modules required to build a RAG. Believe it or not, each of these components have a lot of additional research to make this simple RAG turn into CHAD-rag. Let’s look into each of the major components in this list, starting with chunking.
By the way, this article is based on this 17-minute Youtube video I made on the same topic, covering all the topics in this article. Feel free to check it out after reading this Medium article!
1. Chunking
Chunking is the process of breaking down large documents into smaller, manageable pieces. It might sound simple, but trust me, the way you chunk your data can make or break your RAG pipeline. Whatever chunks you create during preprocessing will eventually get retrieved during inference. If you make the size of chunks too small — like each sentence — then it might be difficult to retrieve them through search because they capture very little information. If the chunk size is too big — like inserting entire Wikipedia articles — the retrieved passages might end up confusing the LLM because you are sending large bodies of texts at once.
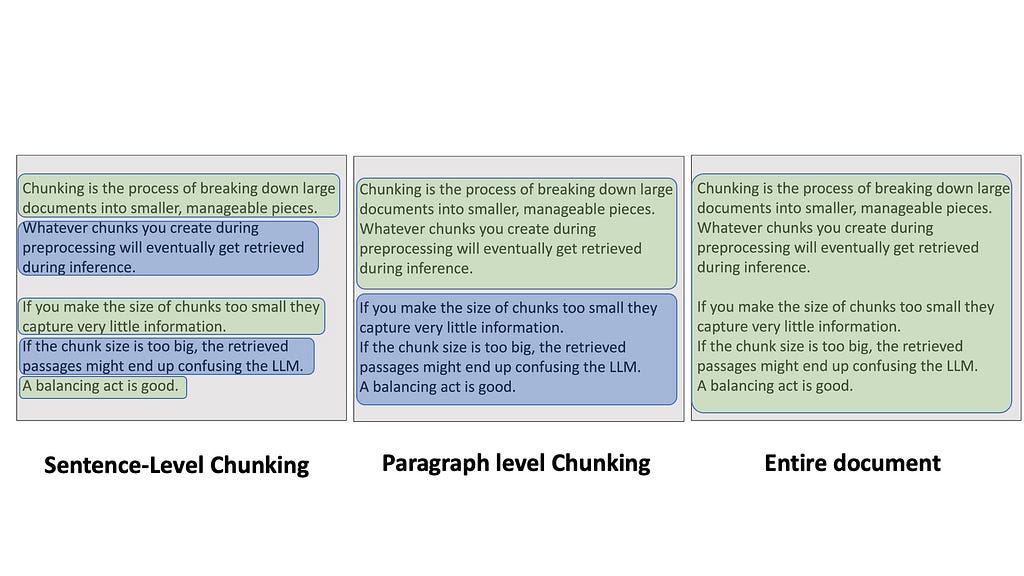
Some frameworks use LLMs to do chunking, for example by extracting simple factoids or propositions from the text corpus, and treat them as documents. This could be expensive because the larger your dataset, the more LLM calls you’ll have to make.
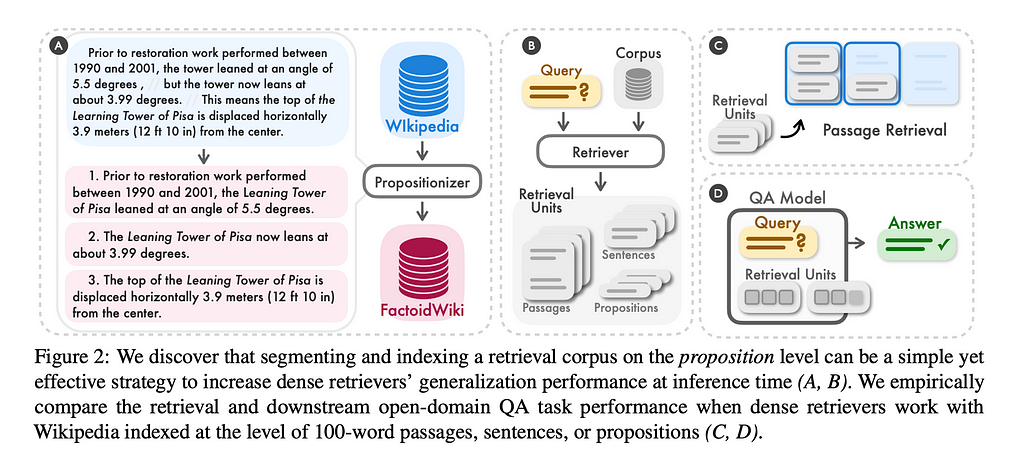
Structural Chunking
Quite often we may also deal with datasets that inherently have a known structure or format. For example, if you want to insert code into your database, you can simply split each script by the function names or class definitions. For HTML pages like Wikipedia articles, you can split by the heading tags — for example, split by the H2 tags to isolate each sub-chapter.
Contextual Chunking
But there are some glaring issues with the types of chunking we have discussed so far. Suppose your dataset consists of tens of thousands of paragraphs extracted from all Sherlock Holmes books. Now the user has queried something general like what was the first crime in Study in Scarlet? What do you think is going to happen?
The problem is that since each documented is an isolated piece of information, we don’t know which chunks are from the book Study in Scarlet. Therefore, later on during retrieval, we will end up fetch a bunch of passages about the topic “crime” without knowing if it’s relevant to the book. To resolve this, we can use something known as contextual chunking.
Enter Contextual Chunking
A recent blogpost from Anthropic describes it as prepending chunk-specific explanatory context to each chunk before embedding. Basically, while we are indexing, we would also include additional information relevant to the chunk — like the name of the book, the chapter, maybe a summary of the events in the book. Adding this context will allow the retriever to find references to Study in Scarlett and crimes when searching, hopefully getting the right documents from the database!
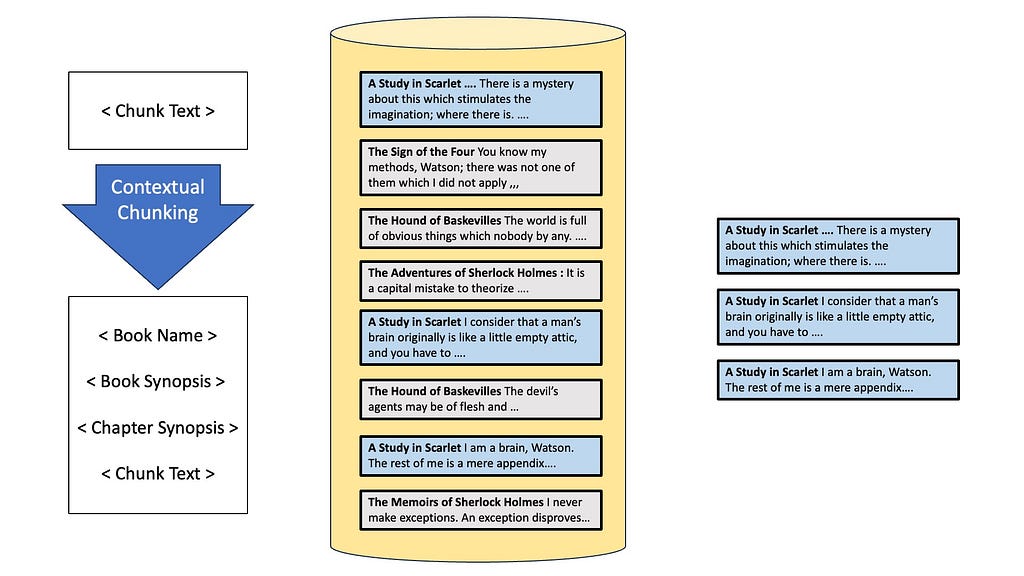
There are other ways to solve the problem of finding the right queries — like metadata filtering, We will talk about this later when we talk about Databases.
2. Data Conversion
Next, we come to the data-conversion stage. Note that whatever strategy we used to convert the documents during preprocessing, we need to use it to search for similarity later, so these two components are tightly coupled.
Two of the most common approaches that have emerged in this space are embedding based methods and keyword-frequency based methods like TF-IDF or BM-25.
Embedding Based Methods
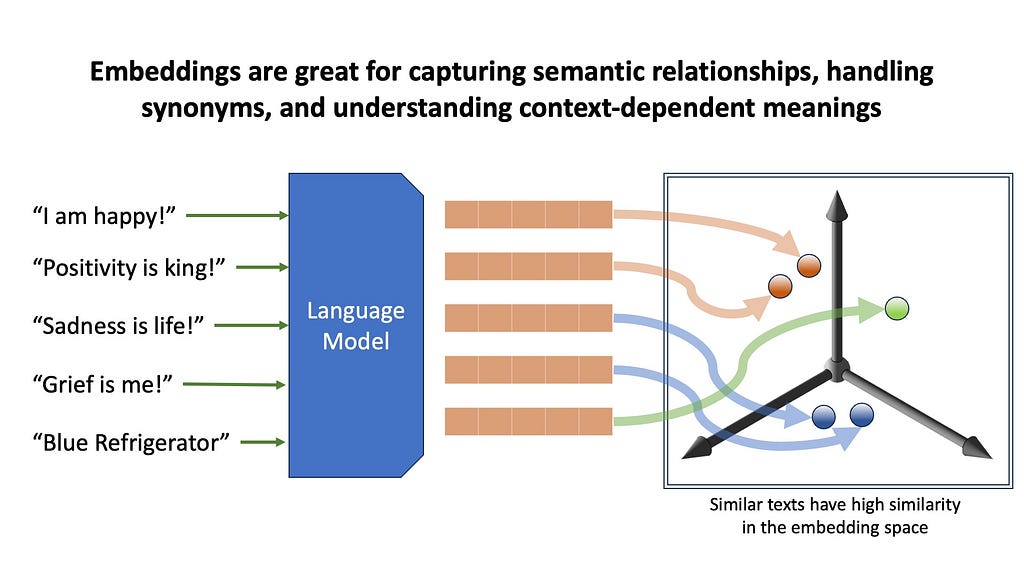
We’ll start with embedding-based methods. Here, we use pretrained transformer models to transform the text into high-dimensional vector representations, capturing semantic meaning about the text. Embeddings are great for capturing semantic relationships, handling synonyms, and understanding context-dependent meanings. However, embedding can be computationally intensive, and can sometimes overlook exact matches that simpler methods would easily catch.
When does Semantic Search fail?
For example, suppose you have a database of manuals containing information about specific refrigerators. When you ask a query mentioning a very specific niche model or a serial number, embeddings will fetch documents that kind of resemble your query, but may fail to exactly match it. This brings us to the alternative of embeddings retrieval — keyword based retrieval.
Keyword Based Methods
Two popular keyword-based methods are TF-IDF and BM25. These algorithms focus on statistical relationships between terms in documents and queries.
TF-IDF weighs the importance of a word based on its frequency in a document relative to its frequency in the entire corpus. Every document in our dataset is be represented by a array of TF-IDF scores for each word in the vocabulary. The indices of the high values in this document vector tell us which words that are likely to be most characteristic of that document’s content, because these words appear more frequently in this document and less frequently in others. For example, the documents related to this Godrej A241gX , will have a high TF-IDF score for the phrase Godrej and A241gX, making it more likely for us to retrieve this using TF-IDF.
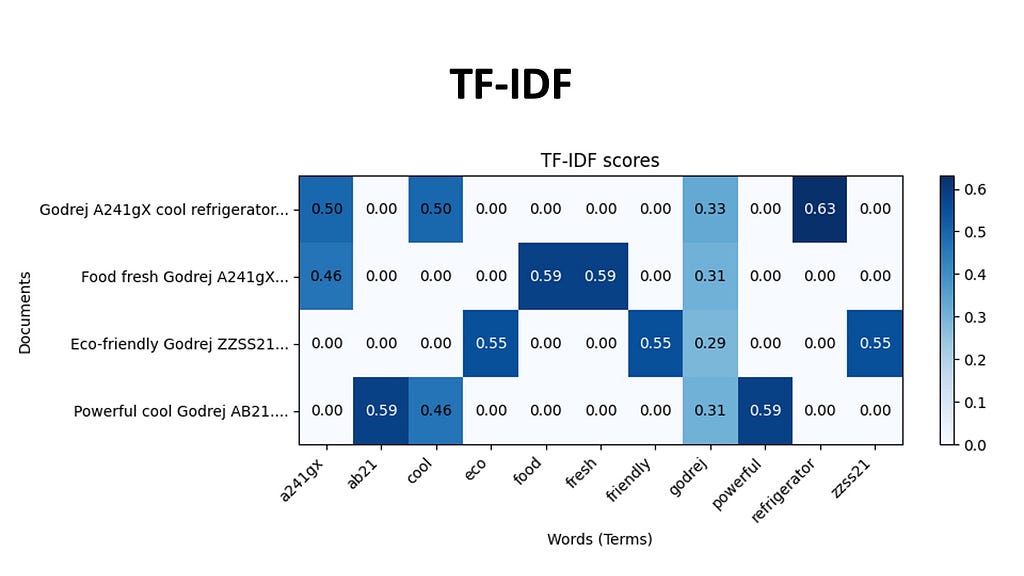
BM25, an evolution of TF-IDF, incorporates document length normalization and term saturation. Meaning that it adjusts the TF-IDF score based on if the document itself is longer or shorter than the average document length in the collection. Term saturation means that as a particular word appears too often in the database, it’s importance decreases.
TF-IDF and BM-25 are great finding documents with specific keyword occurrences when they exactly occur. And embeddings are great for finding documents with similar semantic meaning.
A common thing these days is to retrieve using both keyword and embedding based methods, and combine them, giving us the best of both worlds. Later on when we discuss Reciprocal Rank Fusion and Deduplication, we will look into how to combine these different retrieval methods.
3. Databases
Up next, let’s talk about Databases. The most common type of database that is used in RAGs are Vector Databases. Vector databases store documents by indexing them with their vector representation, be in from an embedding, or TF-IDF. Vector databases specialize in fast similarity check with query vectors, making them ideal for RAG. Popular vector databases that you may want to look into are Pinecone, Milvus, ChromaDB, MongoDB, and they all have their pros and cons and pricing model.
An alternative to vector databases are graph databases. Graph databases store information as a network of documents with each document connected to others through relationships.
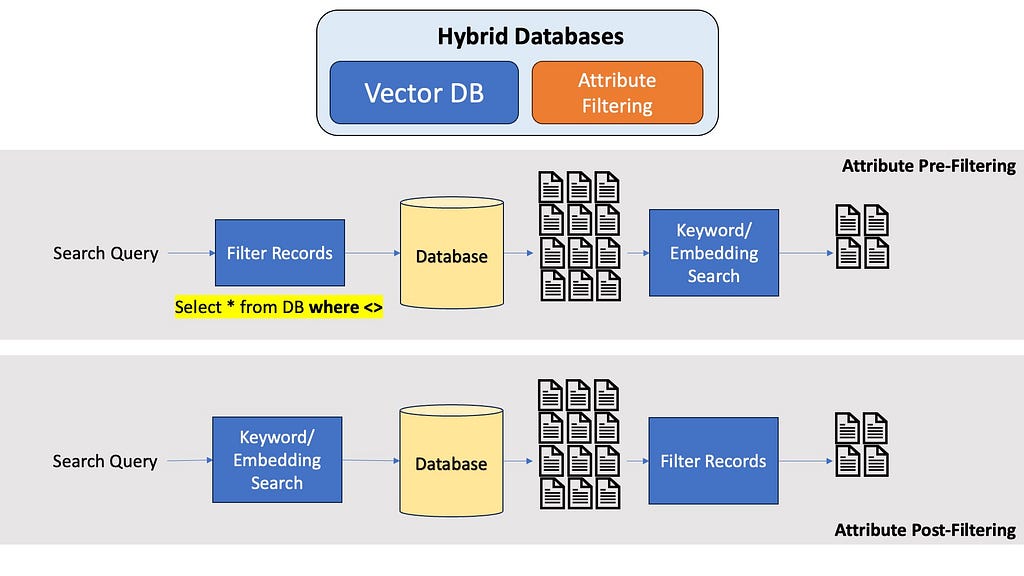
Many modern vector and graph database also allow properties from relational databases, most notably metadata or attribute filtering. If you know the question is about the 5th Harry Potter book, it would be really nice to filter your entire database first to only contain documents from the 5th Harry Potter book, and not run embeddings search through the entire dataset. Optimal metadata filtering in Vector Databases is a pretty amazing area in Computer Science research, and a seperate article would be best for a in-depth discussion about this.
4. Query transformation
Next, let’s move to inferencing starting with query transformation — which is any preprocessing step we do to the user’s actual query before doing any similarity search. Think of it like improving the user’s question to get better answers.
In general, we want to avoid searching directly with the user query. User inputs are usually very noisy and they can type random stuff — we want an additional transformation layer that interprets the user query and turns it into a search query.
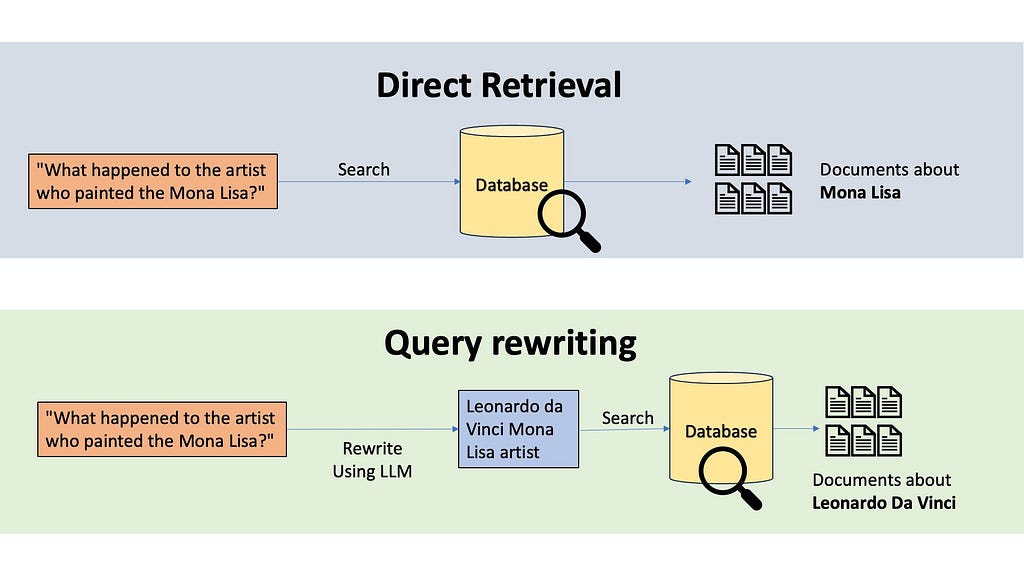
A simple example why Query Rewriting is important
The most common technique to do this transformation is query rewriting. Imagine someone asks, “What happened to the artist who painted the Mona Lisa?” If we do semantic or keyword searches, the retrieved information will be all about the Mona Lisa, not about the artist. A query rewriting system would use an LLM to rewrite this query. The LLM might transform this into “Leonardo da Vinci Mona Lisa artist”, which will be a much fruitful search.
Sometimes we would also use Contextual Query Writing, where we might use additional contexts, like using the older conversation transcript from the user, or if we know that our application covers documents from 10 different books, maybe we can have a classifier LLM that classifies the user query to detect which of the 10 books we are working with. If our database is in a different language, we can also translate the query.
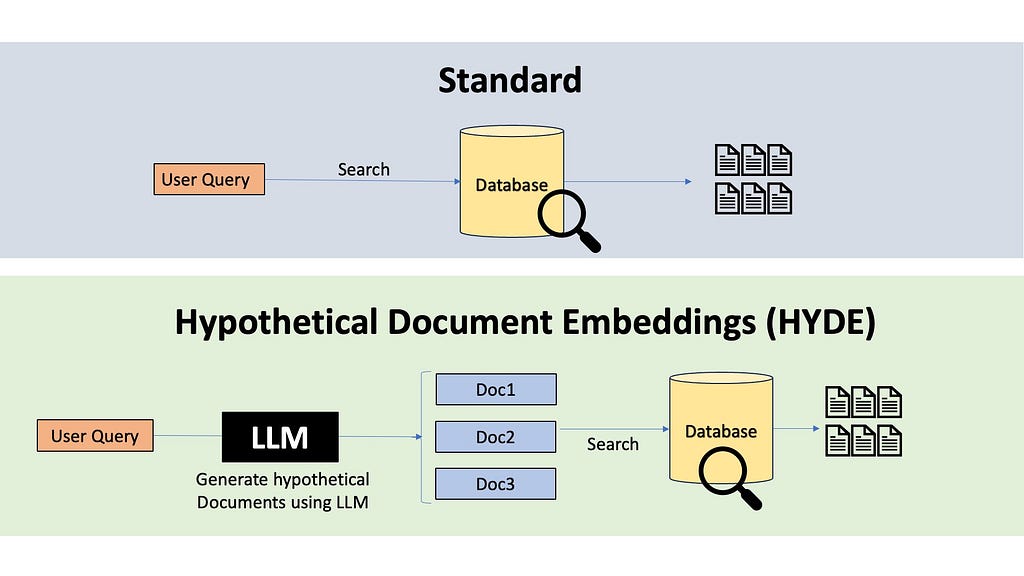
There are also powerful techniques like HYDE, which stands for Hypothetical Document Embedding. HYDE uses a language model to generate a hypothetical answer to the query, and do similarity search with this hypothetical answer to retrieve relevant documents.
Another technique is Multi-Query Expansion where we generate multiple queries from the single user query and perform parallel searches to retrieve multiple sets of documents. The received documents can then later go through a de-duplication step or rank fusion to remove redundant documents.
A recent approach called Astute RAG tries to consolidate externally input knowledge with the LLM’s own internal knowledge before generating answers. There are also Multi-Hop techniques like Baleen programs. They work by performing an initial search, analyzing the top results to find frequently co-occurring terms, and then adding these terms to the original query. This adaptive approach can help bridge the vocabulary gap between user queries and document content, and help retrieve better documents.
5. Post Retrieval Processing
Now that we’ve retrieved our potentially relevant documents, we can add another post-retrieval processing step before feeding information to our language model for generating the answer.
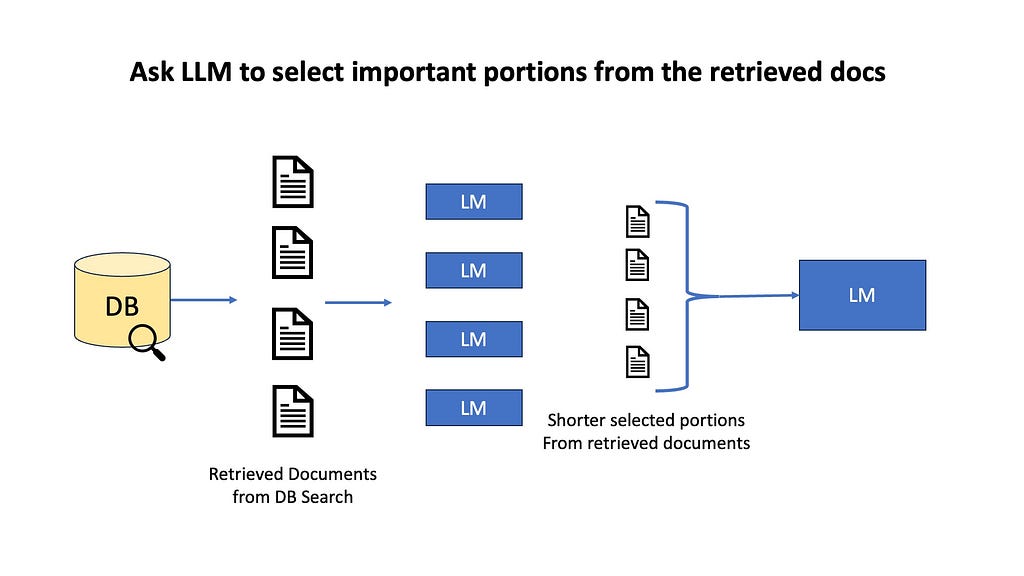
For example, we can do information selection and emphasis, where an LLM selects portion of the retrieved documents that could be useful for finding the answer. We might highlight key sentences, or do semantic filtering where we remove unimportant paragraphs, or do context summarization by fusing multiple documents into one. The goal here is to avoid overwhelming our LLM with too much information, which could lead to less focused or accurate responses.
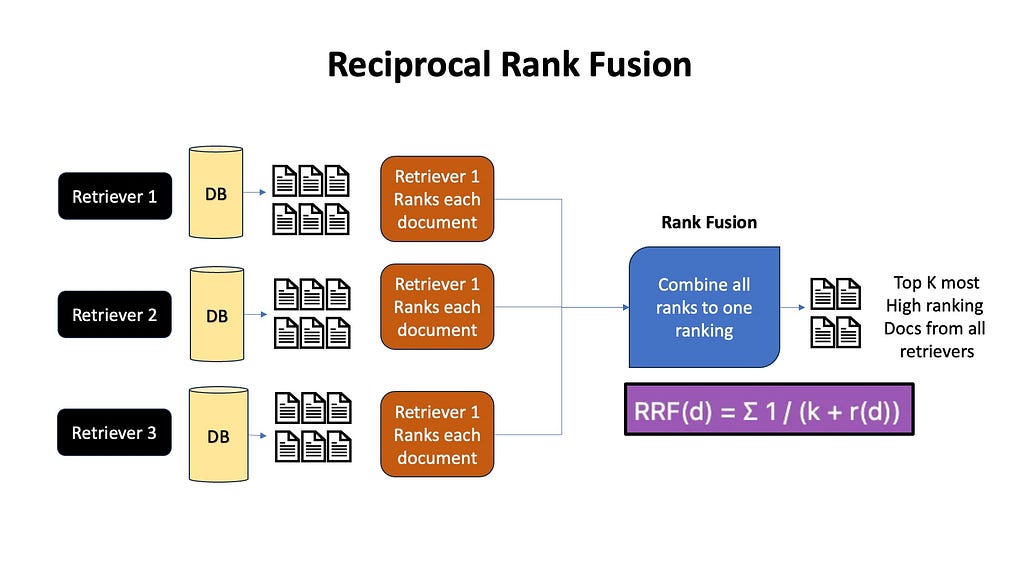
Often we do multiple queries with query expansion, or use multiple retrieval algorithms like Embeddings+BM-25 to separately fetch multiple documents. To remove duplicates, we often use reranking methods like Reciprocal Rank Fusion. RRF combines the rankings from all the different approaches, giving higher weight to documents that consistently rank well across multiple methods. In the end, the top K high ranking documents are passed to the LLM.
FLARE or forward-looking active retrieval augmented generation is an iterative post-retrieval strategy. Starting with the user input and initial retrieval results, an LLM iteratively guesses the next sentence. Then we check if the generated guess contains any low probability tokens indicated here with an underline — if so, we call the retriever to retrieve useful documents from the dataset and make necessary corrections.
Final Thoughts
For a more visual breakdown of the different components of RAGs, do checkout my Youtube video on this topic. The field of LLMs and RAGs are rapidly evolving — a thorough understanding of the RAG framework is incredibly essential to appreciate the pros and cons of each approach and weigh which approaches work best for YOUR use-case. The next time you are thinking of designing a RAG system, do stop and ask yourself these questions —
- What are my data sources?
- How should I chunk my data? Is there inherent structure that comes with my data domain? Do my chunks need additional context (contextual chunking)?
- Do I need semantic retrieval (embeddings) or more exact-match retrieval (BM-25)? What type of queries am I expecting from the user?
- What database should I use? Is my data a graph? Does it need metadata-filtering? How much money do I want to spend on databases?
- How can I best rewrite the user query for easy search hits? Can an LLM rewrite the queries? Should I use HYDE? If LLMs already have enough domain knowledge about my target field, can I use Astute?
- Can I combine multiple different retrieval algorithms and then do rank fusion? (honestly, just do it if you can afford it cost-wise and latency-wise)
The Author
Check out my Youtube channel where I post content about Deep Learning, Machine Learning, Paper Reviews, Tutorials, and just about anything related to AI (except news, there are WAY too many Youtube channels for AI news). Here are some of my links:
Youtube Channel: https://www.youtube.com/@avb_fj
Patreon: https://www.patreon.com/c/NeuralBreakdownwithAVB
Give me a follow on Medium and a clap if you enjoyed this!
References
Vector Databases: https://superlinked.com/vector-db-comparison
Metadata Filtering: https://www.pinecone.io/learn/vector-search-filtering/
Contextual Chunking: https://www.anthropic.com/news/contextual-retrieval
Propositions / Dense X Retrieval: https://arxiv.org/pdf/2312.06648
Hypothetical Document Embeddigs (HYDE): https://arxiv.org/abs/2212.10496
FLARE: https://arxiv.org/abs/2305.06983
The Ultimate Guide to RAGs — Each Component Dissected was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/7ki60W4
via IFTTT


