
GenAI is Reshaping Data Science Teams
Challenges, opportunities, and the evolving role of data scientists

Generative AI (GenAI) opens the door to faster development cycles, minimized technical and maintenance efforts, and innovative use cases that before seemed out of reach. At the same time, it brings new risks — like hallucinations, and dependencies on third-party APIs.
For Data Scientists and Machine Learning teams, this evolution has a direct impact on their roles. A new type of AI project has appeared, with part of the AI already implemented by external model providers (OpenAI, Anthropic, Meta…). Non-AI-expert teams can now integrate AI solutions with relative ease. In this blog post we’ll discuss what all this means for Data Science and Machine Learning teams:
- A wider variety of problems can now be solved, but not all problems are AI problems
- Traditional ML is not dead, but is augmented through GenAI
- Some problems are best solved with GenAI, but still require ML expertise ro run evaluations and mitigate ethical risks
- AI literacy becoming more important within companies, and how Data Scientists play a key role to make it a reality.
A wider variety of problems can now be solved — but not all problems are AI problems
GenAI has unlocked the potential to solve a much broader range of problems, but this doesn’t mean that every problem is an AI problem. Data Scientists and AI experts remain key to identifying when AI makes sense, selecting the appropriate AI techniques, and designing and implementing reliable solutions to solve the given problems (regardless of the solution being GenAI, traditional ML, or a hybrid approach).
To Use or Not to Use Machine Learning
However, while the width of AI solutions has grown, two things need to be taken into consideration to select the right use cases and ensure solutions will be future-proof:
- At any given moment GenAI models will have certain limitations that might negatively impact a solution. This will always hold true as we are dealing with predictions and probabilities, that will always have a degree of error and uncertainty.
- At the same time, things are advancing really fast and will continue to evolve in the near future, decreasing and modifying the limitations and weaknesses of GenAI models and adding new capabilities and features.
If there are specific issues that current LLM versions can’t solve but future versions likely will, it might be more strategic to wait or to develop a less perfect solution for now, rather than to invest in complex in-house developments to overwork and fix current LLMs limitations. Again, Data Scientists and AI experts can help introduce the sensibility on the direction of all this progress, and differentiate which things are likely to be tackled from the model provider side, to the things that should be tackled internally. For instance, incorporating features that allow users to edit or supervise the output of an LLM can be more effective than aiming for full automation with complex logic or fine-tunings.
Differentiation in the market won’t come from merely using LLMs, as these are now accessible to everyone, but from the unique experiences, functionalities, and value products can provide through them (if we are all using the same foundational models, what will differentiate us?, carving out your competitive advantage with AI).
With GenAI solutions, Data Science teams might need to focus less on the model development part, and more on the whole AI system.
Traditional ML is not dead — but is augmented through GenAI
While GenAI has revolutionized the field of AI and many industries, traditional ML remains indispensable. Many use cases still require traditional ML solutions (take most of the use cases that don’t deal with text or images), while other problems might still be solved more efficiently with ML instead of with GenAI.
Far from replacing traditional ML, GenAI often complements it: it allows faster prototyping and experimentation, and can augment certain use cases through hybrid ML + GenAI solutions.
In traditional ML workflows, developing a solution such as a Natural Language Processing (NLP) classifier involves: obtaining training data (which might include manually labelling it), preparing the data, training and fine-tuning a model, evaluating performance, deploying, monitoring, and maintaining the system. This process often takes months and requires significant resources for development and ongoing maintenance.
By contrast, with GenAI, the workflow simplifies dramatically: select the appropriate Large Language Model (LLM), prompt engineering or prompt iteration, offline evaluation, and use an API to integrate the model into production. This reduces greatly the time from idea to deployment, often taking just weeks instead of months. Moreover, much of the maintenance burden is managed by the LLM provider, further decreasing operational costs and complexity.
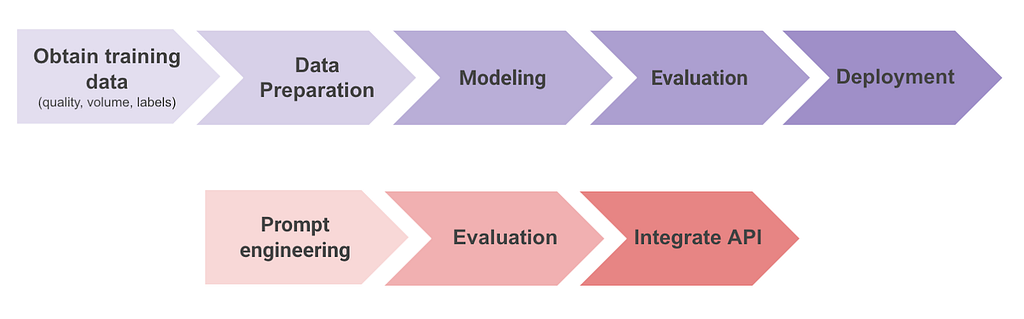
For this reason, GenAI allows testing ideas and proving value quickly, without the need to collect labelled data or invest in training and deploying in-house models. Once value is proven, ML teams might decide it makes sense to transition to traditional ML solutions to decrease costs or latency, while potentially leveraging labelled data from the initial GenAI system. Similarly, many companies are now moving to Small Language Models (SMLs) once value is proven, as they can be fine-tuned and more easily deployed while achieving comparable or superior performances compared to LLMs (Small is the new big: The rise of small language models).
In other cases, the optimal solution combines GenAI and traditional ML into hybrid systems that leverage the best of both worlds. A good example is “Building DoorDash’s product knowledge graph with large language models”, where they explain how traditional ML models are used alongside LLMs to refine classification tasks, such as tagging product brands. An LLM is used when the traditional ML model isn’t able to confidently classify something, and if the LLM is able to do so, the traditional ML model is retrained with the new annotations (great feedback loop!).
Either way, ML teams will continue working on traditional ML solutions, fine-tune and deployment of predictive models, while acknowledging how GenAI can help augment the velocity and quality of the solutions.
Some problems will be better solved with GenAI
The AI field is shifting from using numerous in-house specialized models to a few huge multi-task models owned by external companies. ML teams need to embrace this change and be ready to include GenAI solutions in their list of possible methods to use to stay competitive. Although the model training phase is already done, there is the need to maintain the mindset and sensibility around ML and AI as solutions will still be probabilistic, very different from the determinism of traditional software development.
Despite all the benefits that come with GenAI, ML teams will have to address its own set of challenges and risks. The main added risks when considering GenAI-based solutions instead of in-house traditional ML-based ones are:

- Dependency on third-party models: This introduces new costs per call, higher latency that might impact the performance of real-time systems, and lack of control (as we have now limited knowledge of its training data or design decisions, and provider’s updates can introduce unexpected issues in production).
- GenAI-Specific Risks: we are well aware of the free input / free output relationship with GenAI. Free input introduces new privacy and security risks (e.g. due to data leakage or prompt injections), while free output introduces risks of hallucination, toxicity or an increase of bias and discrimination.
AI Feels Easier Than Ever, But Is It Really?
But still require ML expertise to run evaluations and mitigate ethical risks
While GenAI solutions often are much easier to implement than traditional ML models, their deployment still demands ML expertise, specially in evaluation, monitoring, and ethical risk management.
Just as with traditional ML, the success of GenAI relies on robust evaluation. These solutions need to be assessed from multiple perspectives due to their general “free output” relationship (answer relevancy, correctness, tone, hallucinations, risk of harm…). It is important to run this step before deployment (see picture ML vs GenAI project phases above), usually referred to as “offline evaluation”, as it allows one to have an idea of the behavior and performance of the system when it will be deployed. Make sure to check this great overview of LLM evaluation metrics, which differentiates between statistical scorers (quantitative metrics like BLEU or ROUGE for text relevance) and model-based scorers (e.g., embedding-based similarity measures). DS teams excel in designing and evaluating metrics, even when these metrics can be kind of abstract (e.g. how do you measure usefulness or relevancy?).
Once a GenAI solution is deployed, monitoring becomes critical to ensure that it works as intended and as expected over time. Similar metrics to the ones mentioned for evaluation can be checked in order to ensure that the conclusions from the offline evaluation are maintained once the solution is deployed and working with real data. Monitoring tools like Datadog are already offering LLM-specific observability metrics. In this context, it can also be interesting to enrich the quantitative insights with qualitative feedback, by working close to User Research teams that can help by asking users directly for feedback (e.g. “do you find these suggestions useful, and if not, why?”).
The bigger complexity and black box design of GenAI models amplifies the ethical risks they can carry. ML teams play a crucial role bringing their knowledge about trustworthy AI into the table, having the sensibility about things that can gor wrong, and identifying and mitigating these risks. This work can include running risk assessments, choosing less biased foundational models (ComplAI is an interesting new framework to evaluate and benchmark LLMs on ethical dimensions), defining and evaluating fairness and no-discrimination metrics, and applying techniques and guardrails to ensure outputs are aligned with societal and the organization’s values.
AI Literacy is becoming more important within companies
A company’s competitive advantage will depend not just on its AI internal projects but on how effectively its workforce understands and uses AI. Data Scientists play a key role in fostering AI literacy across teams, enabling employees to leverage AI while understanding its limitations and risks. With their help, AI should act not just as a tool for technical teams but as a core competency across the organization.
To build AI literacy, organizations can implement various initiatives, led by Data Scientists and AI experts like internal trainings, workshops, meetups and hackathons. This awareness can later help:
- Augment internal teams and improve their productivity, by encouraging the use of general-purpose AI or specific AI-based features in tools the teams are already using.
- Identifying opportunities of great potential from within the teams and their expertise. Business and product experts can introduce great project ideas on topics that were previously dismissed as too complex or impossible (and that might realize are now viable with the help of GenAI).
Wrapping it up: the ever Evolving Role of Data Scientists
It is indisputable that the field of Data Science and Artificial Intelligence is changing fast, and with it the role of Data Scientists and Machine Learning teams. While it’s true that GenAI APIs enable teams with little ML knowledge to implement AI solutions, the expertise of DS and ML teams remains of big value for robust, reliable and ethically sound solutions. The re-defined role of Data Scientists under this new context includes:
- Staying up to date with AI progress, to be able to choose the best technique to solve a problem, design and implement a great solution, and make solutions future-proof while acknowledging limitations.
- Adopting a system-wide perspective, instead of focusing solely on the predictive model, becoming more end-to-end and including collaboration with other roles to influence how users will interact (and supervise) the system.
- Continue working on traditional ML solutions, while acknowledging how GenAI can help augment the velocity and quality of the solutions.
- Deep understanding of GenAI limitations and risks, to build reliable and trustworthy AI systems (including evaluation, monitoring and risk management).
- Act as AI Champion across the organization: to promote AI literacy and help non-technical teams leverage AI and identify the right opportunities.
The role of Data Scientists is not being replaced, it is being redefined. By embracing this evolution it will remain indispensable, guiding organizations toward leveraging AI effectively and responsibly.
Looking forward to all the opportunities that will come from GenAI and the Data Scientist role redefinition!
GenAI is Reshaping Data Science Teams was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/x45pB3T
via IFTTT


