
How Did Open Food Facts Fix OCR-Extracted Ingredients Using Open-Source LLMs?
Delve into an end-to-end Machine Learning project to improve the quality of the Open Food Facts database

Open Food Facts’ purpose is to create the largest open-source food database in the world. To this day, it has collected over 3 millions products and their information thanks to its contributors.
Nutritional value, eco-score, product origins,… Various data that define each product and give consumers and researchers insights about what they put in their plates.
This information is provided by the community of users and contributors, who actively add products data, take pictures, and fill any missing data into the database through the mobile app.
Using the product picture, Open Food Facts extracts the ingredients list, typically located on the back of the packaging, through Optical Character Recognition (OCR). The product composition is then parsed and added to the database.

However, it often appears that the text extraction doesn’t go well…
Ingrédients: Jambon do porc, sel, dextrose, arôme naturels, antioxydant: E316, conservateur: E250
^
These typos may seem minimal, but when the list is parsed to extract individual ingredients, such errors create unrecognized ingredients, which harm the quality of the database. Light reflections, folded packaging, low-quality pictures, and other factors all complicate the ingredient parsing process.


Open Food Facts has tried to solve this issue for years using Regular Expressions and existing solutions such as Elasticsearch’s corrector, without success. Until recently.
Thanks to the latest advancements in artificial intelligence, we now have access to powerful Large Language Models, also called LLMs.
By training our own model, we created the Ingredients Spellcheck and managed to not only outperform proprietary LLMs such as GPT-4o or Claude 3.5 Sonnet on this task, but also to reduce the number of unrecognized ingredients in the database by 11%.
This article walks you through the different stages of the project and shows you how we managed to improve the quality of the database using Machine Learning.
Enjoy the reading!
Define the problem
When a product is added by a contributor, its pictures go through a series of processes to extract all relevant information. One crucial step is the extraction of the list of ingredients.
When a word is identified as an ingredient, it is cross-referenced with a taxonomy that contains a predefined list of recognized ingredients. If the word matches an entry in the taxonomy, it is tagged as an ingredient and added to the product’s information.
This tagging process ensures that ingredients are standardized and easily searchable, providing accurate data for consumers and analysis tools.
But if an ingredient is not recognized, the process fails.

For this reason, we introduced an additional layer to the process: the Ingredients Spellcheck, designed to correct ingredient lists before they are processed by the ingredient parser.
A simpler approach would be the Peter Norvig algorithm, which processes each word by applying a series of character deletions, additions, and replacements to identify potential corrections.
However, this method proved to be insufficient for our use case, for several reasons:
- Special Characters and Formatting: Elements like commas, brackets, and percentage signs hold critical importance in ingredient lists, influencing product composition and allergen labeling (e.g., “salt (1.2%)”).
- Multilingual Challenges: the database contains products from all over the word with a wide variety of languages. This further complicates a basic character-based approach like Norvig’s, which is language-agnostic.
Instead, we turned to the latest advancements in Machine Learning, particularly Large Language Models (LLMs), which excel in a wide variety of Natural Language Processing (NLP) tasks, including spelling correction.
This is the path we decided to take.
Evaluate
You can’t improve what you don’t measure.
What is a good correction? And how to measure the performance of the corrector, LLM or non-LLM?
Our first step is to understand and catalog the diversity of errors the Ingredient Parser encounters.
Additionally, it’s essential to assess whether an error should even be corrected in the first place. Sometimes, trying to correct mistakes could do more harm than good:
flour, salt (1!2%)
# Is it 1.2% or 12%?...
For these reasons, we created the Spellcheck Guidelines, a set of rules that limits the corrections. These guidelines will serve us in many ways throughout the project, from the dataset generation to the model evaluation.
The guidelines was notably used to create the Spellcheck Benchmark, a curated dataset containing approximately 300 lists of ingredients manually corrected.
This benchmark is the cornerstone of the project. It enables us to evaluate any solution, Machine Learning or simple heuristic, on our use case.
It goes along the Evaluation algorithm, a custom solution we developed that transform a set of corrections into measurable metrics.
The Evaluation Algorithm
Most of the existing metrics and evaluation algorithms for text-relative tasks compute the similarity between a reference and a prediction, such as BLEU or ROUGE scores for language translation or summarization.
However, in our case, these metrics fail short.
We want to evaluate how well the Spellcheck algorithm recognizes and fixes the right words in a list of ingredients. Therefore, we adapt the Precision and Recall metrics for our task:
Precision = Right corrections by the model / Total corrections made by the model
Recall = Right corrections by the model / Total number of errors
However, we don’t have the fine-grained view of which words were supposed to be corrected… We only have access to:
- The original: the list of ingredients as present in the database;
- The reference: how we expect this list to be corrected;
- The prediction: the correction from the model.
Is there any way to calculate the number of errors that were correctly corrected, the ones that were missed by the Spellcheck, and finally the errors that were wrongly corrected?
The answer is yes!
Original: "Th cat si on the fride,"
Reference: "The cat is on the fridge."
Prediction: "Th big cat is in the fridge."
With the example above, we can easily spot which words were supposed to be corrected: The , is and fridge ; and which words were wrongly corrected: on into in. Finally, we see that an additional word was added: big .
If we align these 3 sequences in pairs, original-reference and original-prediction , we can detect which words were supposed to be corrected, and those that weren’t. This alignment problem is typical in bio-informatic, called Sequence Alignment, whose purpose is to identify regions of similarity.
This is a perfect analogy for our spellcheck evaluation task.
Original: "Th - cat si on the fride,"
Reference: "The - cat is on the fridge."
1 0 0 1 0 0 1
Original: "Th - cat si on the fride,"
Prediction: "Th big cat is in the fridge."
0 1 0 1 1 0 1
FN FP TP FP TP
By labeling each pair with a 0 or 1 whether the word changed or not, we can calculate how often the model correctly fixes mistakes (True Positives — TP), incorrectly changes correct words (False Positives — FP), and misses errors that should have been corrected (False Negatives — FN).
In other words, we can calculate the Precision and Recall of the Spellcheck!
We now have a robust algorithm that is capable of evaluating any Spellcheck solution!
You can find the algorithm in the project repository.
Large Language Models
Large Language Models (LLMs) have proved being great help in tackling Natural Language task in various industries.
They constitute a path we have to explore for our use case.
Many LLM providers brag about the performance of their model on leaderboards, but how do they perform on correcting error in lists of ingredients? Thus, we evaluated them!
We evaluated GPT-3.5 and GPT-4o from OpenAI, Claude-Sonnet-3.5 from Anthropic, and Gemini-1.5-Flash from Google using our custom benchmark and evaluation algorithm.
We prompted detailed instructions to orient the corrections towards our custom guidelines.
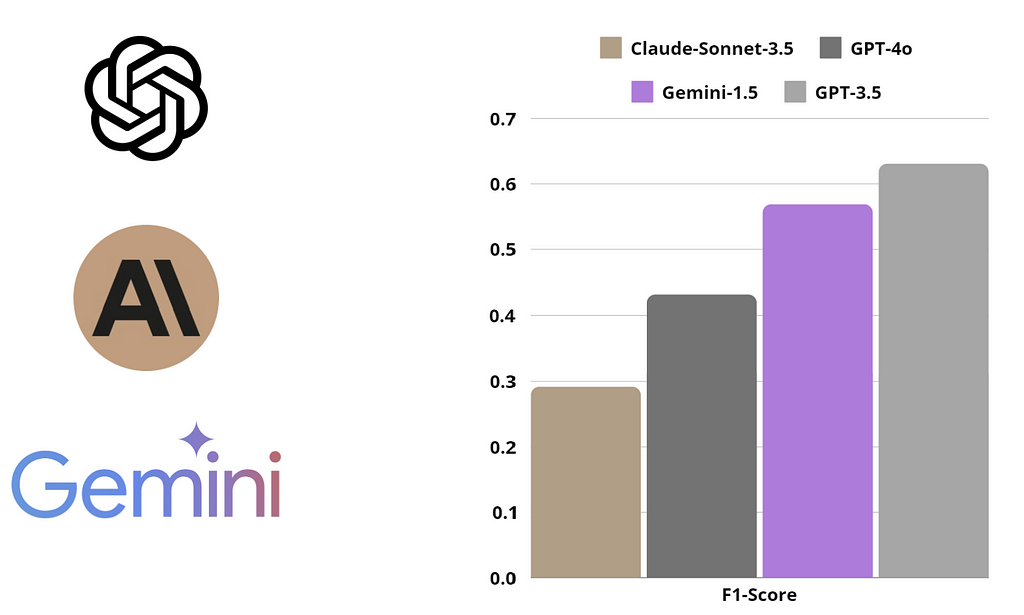
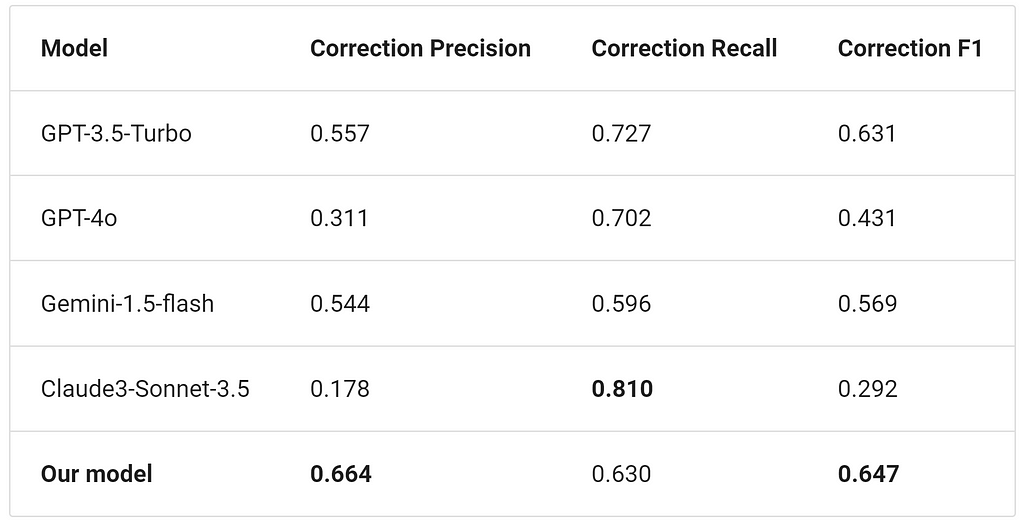
GPT-3.5-Turbo delivered the best performance compared to other models, both in terms of metrics and manual review. Special mention goes to Claude-Sonnet-3.5, which showed impressive error corrections (high Recall), but often provided additional irrelevant explanations, lowering its Precision.
Great! We have an LLM that works! Time to create the feature in the app!
Well, not so fast…
Using private LLMs reveals many challenges:
- Lack of Ownership: We become dependent on the providers and their models. New model versions are released frequently, altering the model’s behavior. This instability, primarily because the model is designed for general purposes rather than our specific task, complicates long-term maintenance.
- Model Deletion Risk: We have no safeguards against providers removing older models. For instance, GPT-3.5 is slowly being replace by more performant models, despite being the best model for this task!
- Performance Limitations: The performance of a private LLM is constrained by its prompts. In other words, our only way of improving outputs is through better prompts since we cannot modify the core weights of the model by training it on our own data.
For these reasons, we chose to focus our efforts on open-source solutions that would provide us with complete control and outperform general LLMs.
Train our own model
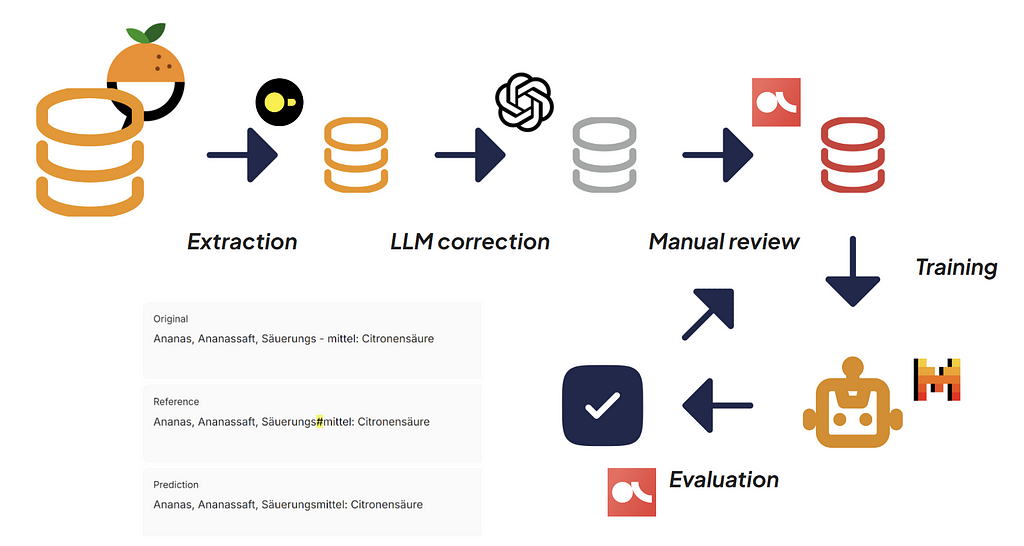
Any machine learning solution starts with data. In our case, data is the corrected lists of ingredients.
However, not all lists of ingredients are equal. Some are free of unrecognized ingredients, some are just so unreadable they would be no point correcting them.
Therefore, we find a perfect balance by choosing lists of ingredients having between 10 and 40 percent of unrecognized ingredients. We also ensured there’s no duplicate within the dataset, but also with the benchmark to prevent any data leakage during the evaluation stage.
We extracted 6000 uncorrected lists from the Open Food Facts database using DuckDB, a fast in-process SQL tool capable of processing millions of rows under the second.
However, those extracted lists are not corrected yet, and manually annotating them would take too much time and resources…
However, we have access to LLMs we already evaluated on the exact task. Therefore, we prompted GPT-3.5-Turbo, the best model on our benchmark, to correct every list in respect of our guidelines.
The process took less than an hour and cost nearly 2$.
We then manually reviewed the dataset using Argilla, an open-source annotation tool specialized in Natural Language Processing tasks. This process ensures the dataset is of sufficient quality to train a reliable model.
We now have at our disposal a training dataset and an evaluation benchmark to train our own model on the Spellcheck task.
Training
For this stage, we decided to go with Sequence-to-Sequence Language Models. In other words, these models take a text as input and returns a text as output, which suits the spellcheck process.
Several models fit this role, such as the T5 family developed by Google in 2020, or the current open-source LLMs such as Llama or Mistral, which are designed for text generation and following instructions.
The model training consists in a succession of steps, each one requiring different resources allocations, such as cloud GPUs, data validation and logging. For this reason, we decided to orchestrate the training using Metaflow, a pipeline orchestrator designed for Data science and Machine Learning projects.
The training pipeline is composed as follow:
- Configurations and hyperparameters are imported to the pipeline from config yaml files;
- The training job is launched in the cloud using AWS Sagemaker, along the set of model hyperparameters and the custom modules such as the evaluation algorithm. Once the job is done, the model artifact is stored in an AWS S3 bucket. All training details are tracked using Comet ML;
- The fine-tuned model is then evaluated on the benchmark using the evaluation algorithm. Depending on the model sizem this process can be extremely long. Therefore, we used vLLM, a Python library designed to accelerates LLM inferences;
- The predictions against the benchmark, also stored in AWS S3, are sent to Argilla for human-evaluation.
After iterating over and over between refining the data and the model training, we achieved performance comparable to proprietary LLMs on the Spellcheck task, scoring an F1-Score of 0.65.
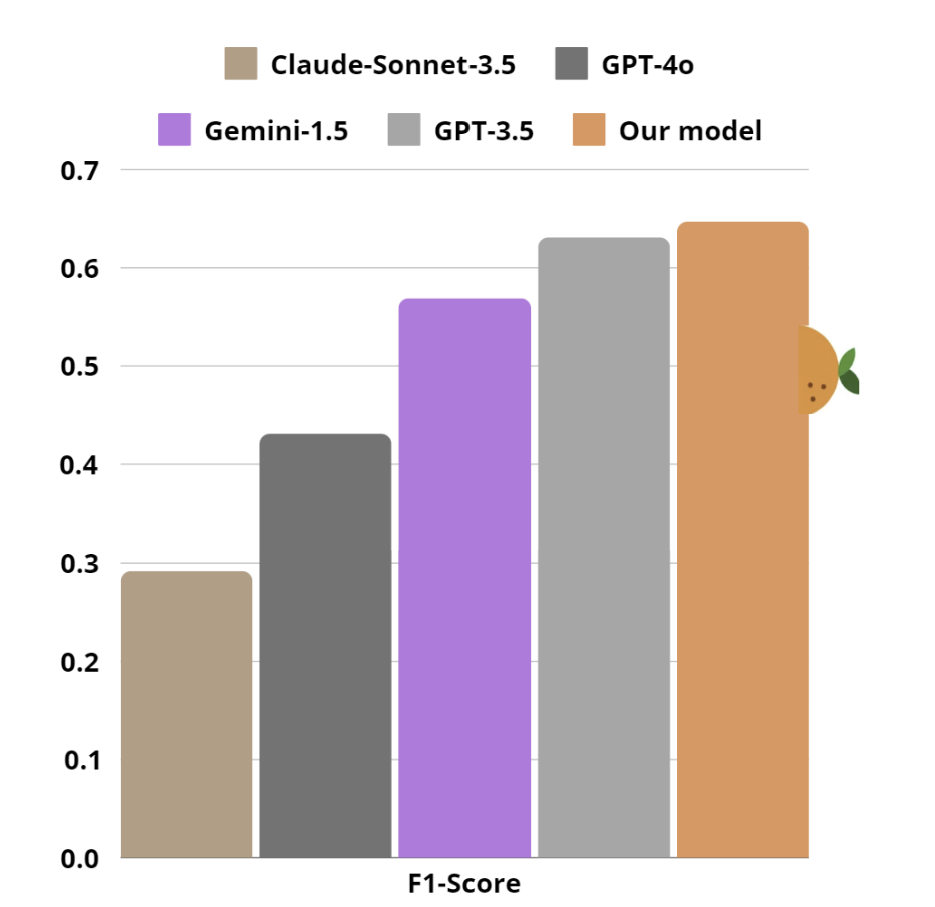
The model, a fine-tuned Mistral-7B-Base-v0.3, is available on the Hugging Face platform and is publicly available, along its dataset and evaluation benchmark.
openfoodfacts/spellcheck-mistral-7b · Hugging Face
Furthermore, we estimated the Spellcheck reduced the number of unrecognized ingredients by 11%, which is promising!
Now comes the final phase of the project: integrating the model into Open Food Facts.
Deployment & Integration
Our model is big!
7 billions parameters, which means 14 GB of memory required to run it in float16, without considering the 20% overhead factor.
Additionally, large models often mean low throughput during inference, which can make them inappropriate for real-time serving. We need GPUs with large memory to run this model in production, such as the Nvidia L4, which is equipped with 24GB of VRAM.
But the price of running these instances in the cloud is quite expensive…
However, a possibility to provide a real-time experience for our users, without requiring GPU instances running 24/7, is batch inference.
Lists of ingredients are processed in batches by the model on a regular basis, then stored in the database. This way, we pay only for the resources used during the batch processing!
Batch Job
We developed a batch processing system to handle large-scale text processing using LLMs efficiently with Google Batch Job.
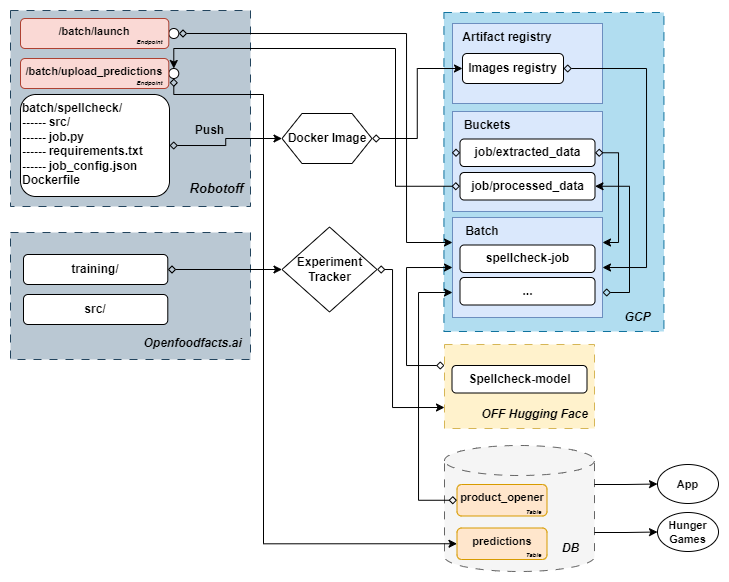
The process begins by extracting data from the Open Food Facts database using DuckDB, which processes 43 GB of data in under 2 minutes!
The extracted data is then sent to a Google Bucket, triggering a Google Batch Job.
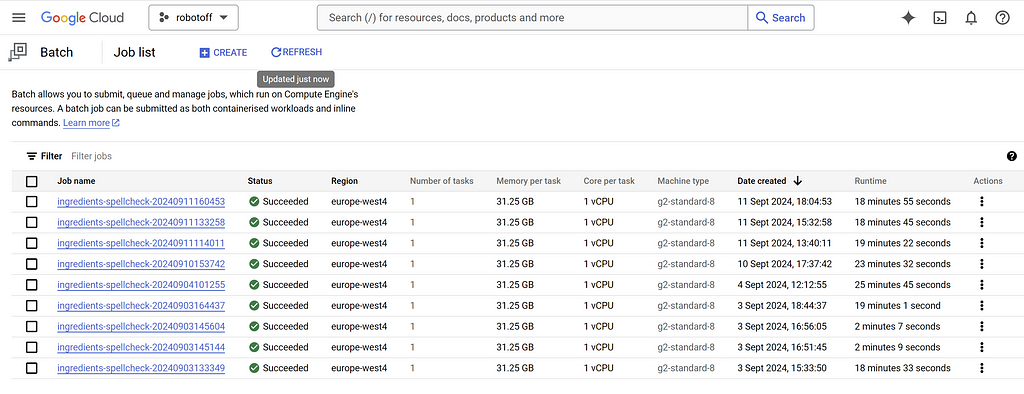
This job uses a pre-prepared Docker image containing all necessary dependencies and algorithms. To optimize the resource-intensive LLM processing, we reuse vLLM achieving impressive performances, correcting 10,000 lists of ingredients in 20 minutes only with a GPU L4!
After successful processing, the corrected data is saved in a intermediate database containing the predictions of all models in Open Food Facts, served by Robotoff.
When a contributor modifies a product details, they’re presented with the spellcheck corrections, ensuring users remain the key decision-makers in Open Food Facts’ data quality process.
This system allows Open Food Facts to leverage advanced AI capabilities for improving data quality while preserving its community-driven approach.
Conlusion
In this article, we walked you through the development and the integration of the Ingredients Spellcheck, an LLM-powered up feature to correct OCR-extracted lists of ingredients.
We first developed a set of rules, the Spellcheck Guidelines, to restrict the corrections . We created a benchmark of corrected lists of ingredients that, along a custom evaluation algorithm, to evaluate any solution to the problem.
With this setup, we evaluated various private LLMs and determined that GPT-3.5-Turbo was the most suitable model for our specific use case. However, we also demonstrated that relying on a private LLM imposes significant limitations, including lack of ownership and restricted opportunities to improve or fine-tune such a large model (175 billion parameters).
To address these challenges, we decided to develop our own model, fine-tuning it on synthetically corrected texts extracted from the database. After several iterations and experiments, we successfully achieved good performances with an open-source model. Not only did we match private LLMs performance, it also solved the ownership problem we were facing, giving us full control over our model.
We then integrated this model into the Open Food Facts using batch inference deployment, enabling us to process thousands of lists on a regular basis. The predictions are stored in Robotoff database as Insights before being validated by contributors, leaving OFF data quality ownership to contributors.
Next step
The Spellcheck integration is still a work in progress. We are working on designing the user interface to propose ML generated corrections and let contributors accept, deny, or modify corrections. We expect fully integrating the feature by the end of the year.
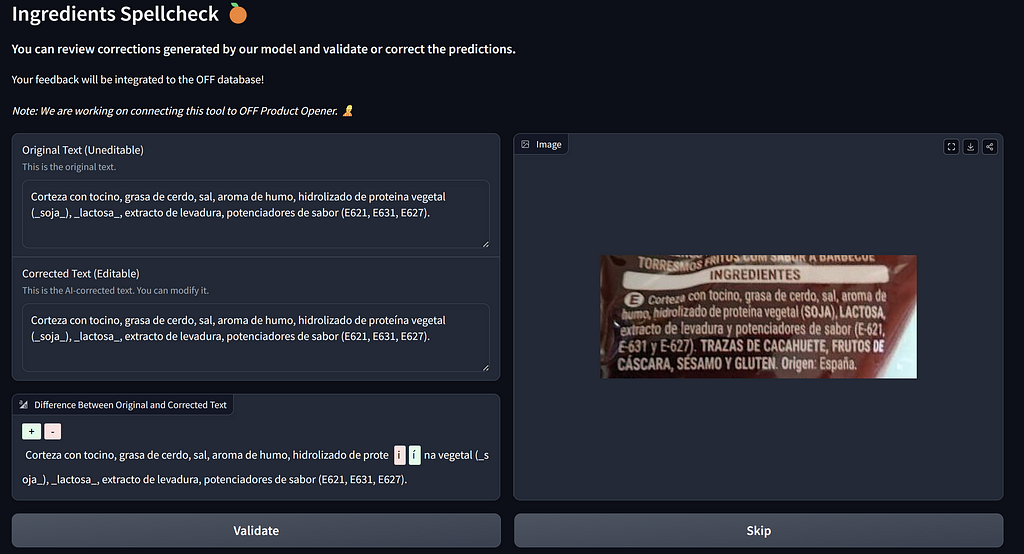
Additionally, we plan to continue refining the model through iterative improvements. Its performance can be significantly enhanced by improving the quality of the training data and incorporating user feedback. This approach will allow us to fine-tune the model continuously, ensuring it remains highly effective and aligned with real-world use cases.
The model, along its datasets, can be find in the official Hugging Face repository. The code used to developped this model is available in the OpenFoodFacts-ai/spellcheck Github repository.
Thank you for reading that far! We hope you enjoyed the reading.
If you too, you want to contribute to Open Food Facts, you can:
- Contribute to the Open Food Facts GitHub: explore open issues that align with your skills,
- Download the Open Food Facts mobile app: add new products to the database or improve existing ones by simply scanning their barcodes,
- Join the Open Food Facts Slack and start discussing with other contributors in the OFF community.
We can’t wait to see you join the community!
Don’t hesitate to check our other articles:
DuckDB & Open Food Facts: the largest open food database in the palm of your hand 🦆🍊
How Did Open Food Facts Fix OCR-Extracted Ingredients Using Open-Source LLMs? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/oCbk2F6
via IFTTT


