
How to Develop an Effective AI-Powered Legal Assistant
Create a machine-learning-based search into legal decisions
In this article, I describe how I created an application to search for supreme court decisions in Norway. This application is a useful tool for quickly gaining insights into decisions made on different topics, which is especially interesting if you want to learn the Supreme Court’s stance on particular subjects. It can also be interesting if you want to learn more about creating advanced AI-search to find documents.

You can access the application developed in this article here:
Motivation
My motivation for this article is to describe the process of creating a legal assistant using the latest technology within language models. This tool has the potential to save enormous amounts of time for lawyers doing research into subjects. In the future, I plan to expand the application to include retrieving relevant laws, published legal opinions from relevant actors, and so on. This can then act as a complete tool for lawyers to gain insights into the subject they are considering quickly. In today’s world, juniors at law firms spend a lot of time gathering all of this information. I aim to develop an application that makes this process far more effective and allows lawyers to spend more time on other tasks. This can both help law firms further help their clients, as they are working more effectively, and also save clients money, considering the lawyer's time is spent more effectively.
I have already written articles describing subprocesses in developing this application. In How to Create an Appealing Frontend for Your ML Application, I detailed how I made the website using the v0 language model. I also wrote a more technical description of developing the search part of this website for Towards Data Science in Implementing Anthropic’s Contextual Retrieval for Powerful RAG Performance, linked below.
Implementing Anthropic’s Contextual Retrieval for Powerful RAG Performance
Considering this part went in-depth on the technical parts of creating this application, this article will focus more on the high-level parts of creating the application.
Table of Contents
· Motivation
· Table of Contents
· Retrieving data
· Storing data in AWS
· Developing RAG search
· Creating a website
· Deployment
∘ Hosting the frontend
∘ Hosting the backend
· Issues I encountered
· Conclusion
Retrieving data
The data used for this application is court rulings from the Supreme Court of Norway. You can find the court rulings on the Supreme Court website. The problem here, however, is that it is difficult to find particular rulings, as the search function on the website is very basic. This is among the reasons I decided to create my application. I also add a disclaimer that these court rulings are exempted from copyright law (meaning they may be used commercially) in Norway due to being documents of public interest.
To create my application, I needed to extract all the court rulings available on the website. Naturally, one option is to extract all the court rulings manually, but this would take a lot of time. Instead, I created a web scraper that could extract each case from the website. This is acceptable because the court rulings are exempted from copyright law as mentioned above. The scraping is possible since the format of the URLs on the website are very predictable. They all start from one base URL:
- https://ift.tt/8ZWJSsr
You can then find cases from each year by adding the year to the end of the URL (note that the format sometimes changes slightly, so you have to check the different possible formats)
- https://ift.tt/VGwNErD
- https://ift.tt/L3AYIOM
- https://ift.tt/JiKcm7W
- etc
Given each of these links, you can then extract all the links on the site, where each link contains one court ruling. For example, from 2022, you can extract
- https://ift.tt/hnymZKC
- https://ift.tt/d7yHn0P
- https://ift.tt/Oj7gQhP
You can then go into each of these links and extract the contents of the court ruling. I decided to grab the following information
- Headline
- Unique case number (HR-2022–2469, for example. A unique identifier for the case)
- The text body
- The link to the PDF containing the full court ruling
To extract this information, you have to inspect the website, find where the different information is stored, and then use a package like Selenium to extract the contents. Note that the contents of the pages are dynamic, so you have to use a package like Selenium to extract the content (simply using BeatifulSoup to extract the HTML doesn't work)
Storing data in AWS
After I extracted all the data I needed, I had to store it somewhere. Since I have experience working with AWS before, and I received some credits there, I decided to go with AWS. The architecture for my application is shown below:
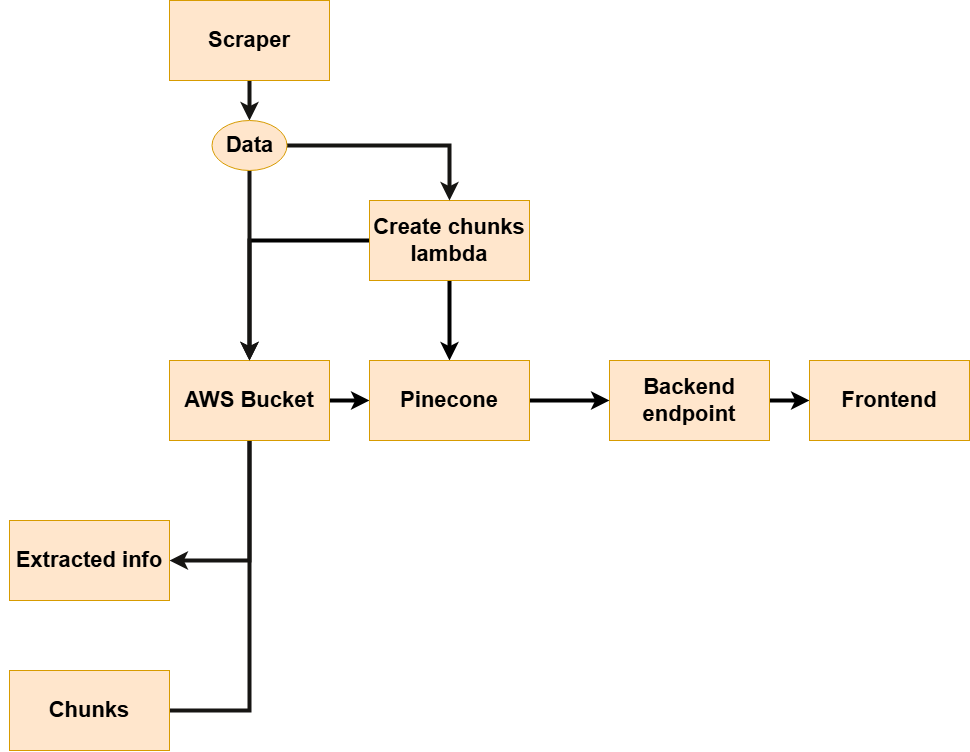
I first have my scraper, which extracts the data I need (the Supreme Court rulings). This data is sent straight to the AWS bucket and stored under the prefix extracted info. The data is also sent to a lambda, which creates chunks. I have set this lambda up to trigger whenever a new file (a new court ruling) is uploaded. The text from these chunks is stored in the AWS bucket under the prefix chunks, along with a unique identifier. The chunk text embedding and the unique identifier are also stored in Pinecone, which is used as the vector database. A user can then enter a question (prompt) on the frontend. This prompt is sent to the backend endpoint, which processes and sends it to Pinecone. Pinecone extracts the most relevant chunks for the prompt, and the backend then returns the most relevant court rulings back to the frontend.
Developing RAG search
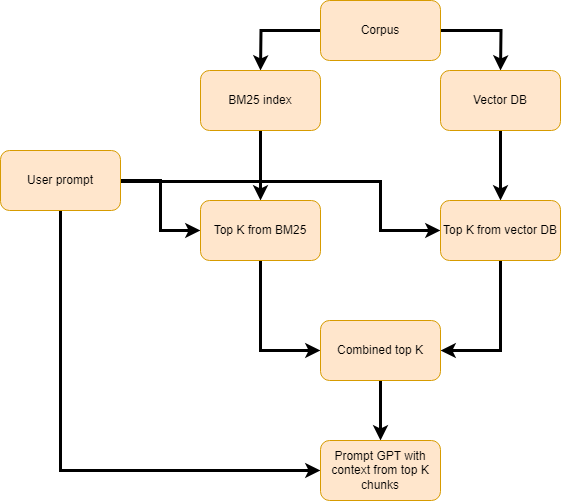
I have previously written an in-depth article on how I created my RAG search for this application, so I will give a more high-level explanation here. When I retrieve a court ruling, I split it into different chunks. These chunks are stored in Pinecone, which is a vector database. This vector database lets you store an embedding of the text. This question is embedded whenever a user asks a question on the frontend. The vector database takes this embedding and compares it to all the embeddings stored in it. The output is the top K most relevant chunks stored in the database (where K is a user-defined variable).
Given the most relevant chunks, I then find the court rulings of these chunks, which are stored in the AWS bucket. I can find these court rulings since the chunks are stored with a unique identifier, which I use to find the court ruling in the AWS bucket. These court rulings are then returned to the frontend.
In addition to providing sources to a user's question, I also provide an answer to the question. This question is generated using the GPT-4o language model. The language model is prompted using the user's question and then given the different court rulings as sources. The language model is then able to respond accurately to the user's question using the court rulings as sources. The language model often references the different court rulings it uses to respond to questions (using the unique identifier of the court ruling).
Creating a website
I have also written a more in-depth article on how I created the frontend for this application. In short, I used the v0 by Vercel language model to write much of the frontend design code. Designing a frontend application is not what I prefer to spend my time on, and the v0 language model saved me a tremendous amount of time by simply creating a good-looking design using some prompts. There were, however, some parts of the frontend I had to do myself, which v0 struggled somewhat with. One was to adjust the API request to my backend to the expected format. Another part was hosting the frontend application, which I did with Vercel. I’ll go into more detail about that in the next section.
Deployment
Hosting the frontend
After developing the frontend and the application, the next step was to host it. Initially, I created only the backend of my project and hosted it with a simple Streamlit application. Streamlit is a powerful way to get your product quickly into production so anyone can use it. Unfortunately, however, Streamlit also has some limitations.
- It’s slow. Especially if no one has used your application in a bit, it needs to cold start, which takes even longer
- It looks cheap. Using a prepaid website with a locked design that many other websites use looks cheap and might scare off some consumers of your product
- You can only host one project with a private code base. If you want to host more projects, you must make your code publicly available, which is often undesirable.
Thus, I decided to create my website, which looks much better. Hosting the frontend is relatively simple; you link your next.js project on Vercel and link it to a particular branch. Whenever you push code into this branch, Vercel automatically triggers a new deployment.
Hosting the backend
Hosting the backend is more complicated. Initially, I tried to host the backend as an EC2 instance on AWS to ensure I always had an instance up and running and could provide quick response times to my users. After working on it a bit, however, I realized creating a Lambda function to host my backend is cheaper and much more straightforward. The Lambda function has a sub-second cold start-up time, which is fast enough for my application's needs. I then host it using an HTTPS endpoint to make it accessible to my frontend. I could also use the AWS CDK on my frontend, but I decided it would be easier to access my lambda function using an HTTPS endpoint.
After setting up the lambda endpoint, my code was almost up and running. The last hurdle was confirming CORS, which can always be finicky when working on web applications. However, it was not too complicated in this case, as I could configure all my CORS settings in my AWS CDK stack and lambda handler. My application is up and running after configuring my frontend to have access to the back endpoint.
Issues I encountered
I naturally ran into a lot of different issues while developing this application. One of the more significant challenges I faced was when I was working on setting up the EC2 instance in AWS. Setting up an HTTPS application with EC2 in AWS was relatively tricky. My solution to this was that setting up a lambda is easier and cheaper for my use case. So, the most critical takeaway is considering what service you should use to host your application. I think lambdas are often the easiest and cheapest way to host your application for AWS.
Another issue I encountered was the aforementioned CORS issue. Dealing with CORS errors is a standard when developing web applications, and it can be quirky to figure out how to solve them. Luckily, in this case, you can configure all the CORS settings using the AWS CDK (the code where you create your lambda function) and the lambda handler function (the function that processes a request). This makes solving CORS errors a lot simpler using AWS.
Furthermore, I am also currently struggling with the response time. The current time a user sends a query until they receive a response is 8–9 seconds when I did my tests. I think this is far too long for a good user experience. I remember reading a Google study on response time and user retention and how longer response times turn away a lot of users. Therefore, I need to reduce the response time for a user query. Unfortunately, however, the response time is limited by the OpenAI API, as almost all of the waiting time is spent by OpenAI answering the user query. There are several ways I can attempt to solve this problem. One is to change the API provider to one that can provide a faster response time. This is a simple change as I only need to change the API call in my code, and is thus something I should try out. Another fix I can attempt is to use a different language model that can provide a faster response. Lastly, I could also try to reduce the prompt's size, ensuring more rapid responses.
Overall, there were many hurdles in creating this application, but most of them can be solved using a Google search or prompting ChatGPT. Some challenges took longer to solve than others, but that is simply a part of working as an ML/Software engineer.
Conclusion
In this article, I discuss how I created my legal assistant application, which allows users to ask questions about Supreme Court decisions in Norway. This is an effective way of accessing that extensive archive of Supreme Court decisions, which could otherwise be challenging to navigate. I first discussed retrieving the data for the Supreme Court decisions, which is done using a web scraper. I then proceeded to discuss my application's architecture, how I store all the information, and respond to user queries. Furthermore, I discussed developing the RAG search used to respond to user queries and how I made the frontend for the website. Lastly, I also discussed hosting both the frontend and the backend of the application and the various challenges I faced throughout working on this project.
How to Develop an Effective AI-Powered Legal Assistant was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/zEdKat1
via IFTTT


