
Python Might Be Your Best PDF Data Extractor
A step-by-step guide on getting the most of lengthy data reports, within seconds

Portable Document Format files (PDFs) have been floating around in the digital world since their inception by Adobe in the early 1990s. Designed to preserve formatting across different devices, PDFs quickly became the go-to format for sharing everything from contracts to annual reports and complex financial documents.
In finance, legal services, and many (if not all) other sectors, PDFs have remained a mainstay to this day. Anyone can open a PDF, and it always displays the same way, no matter what reader is being used. This is an advantage for files that should not change — unlike, say, editable word or PowerPoint files.
One disadvantage of PDFs is that they are meant for human eyes. In other words, if you want to process a 400-page report, initially you might need to open it manually and at least scroll through to the relevant sections yourself. This is a problem when working with large volumes of data, stored in PDFs.
Training chatbots on such large files remains challenging, not to mention energy-consuming. Even when you succeed, state-of-the-art chatbots give unreliable answers at best when queried about the contents. Fine-tuning such chatbots to the type of data in your PDFs only gets you so far, too. (We know because we have tried — at length.)
Python, on the other hand, comes with a whole Swiss army knife’s worth of libraries to deal with different PDFs. As we will see in this piece, it is not 100 percent perfect all the time either. It does come pretty close, though. Compared with manual extraction, which we were doing at the beginnings of Wangari, we’re looking at some 90 to 95 percent worth of time savings.
Because no PDF is the same as another, it is worth figuring out which one of Python’s libraries is worth using for which type of data. We therefore present a quick overview of the most popular libraries below. We then proceed to a couple of examples that illustrate how one can use some of these libraries and extract data in seconds once the code is written. Finally, we compare Python’s tools to those available in some other programming languages and more manual approaches, before wrapping up in a conclusion.
A rundown of available PDF extraction tools in Python
Overall, the available tools can be classified as lightweight tools (e.g., Slate, PyPDF2), advanced extraction tools (e.g., pdfplumber, pdfminer.six), OCR-focused tools (pytesseract), and libraries for PDF manipulation (pikepdf, PDFBox).
OCR is industry-lingo for Optical Character Recognition, and will come up some more in this article. As a general rule of thumb, it is better to start with a simpler tool and then work your way up to more advanced ones if the task on hand demands it.
Lightweight Tools like PyPDF2 and Slate are good libraries for simpler text extraction tasks and basic PDF manipulation. Both are capable of splitting, merging, and extracting text from PDFs. They reach their limits, however, with complex layouts, images, and tables.
Advanced Extraction Tools such as pdfplumber and pdfminer.six are useful for PDFs containing tables, images, or otherwise detailed layouts. If your priority is extracting structured content and preserving the layout, then pdfplumber is your friend. If you want more details on other information in the PDF, such as font details and layout information, then pdfminer.six is the tool to go with. It is also a good choice for PDFs with unique encodings, which can occur more often than one might think.
For those focused on Tabular Data Extraction, tabula-py and camelot-py are great options. For simple tables, tabula-py works like a charm. It converts tables in PDFs into pandas DataFrames or CSV files, which can then be analyzed further. If you are handling more complex table structures, for example from research papers or other in-depth reports, camelot-py is useful.
For Image-Based PDFs and OCR Workflows, pdf2image and pytesseract are two key tools. These are also catch-all tools that should work even when you are dealing with some exotically encoded PDF file. Typically, you convert PDF pages into image formats like PNG or JPEG using pdf2image. In a second step, you might use pytesseract for text extraction. Some use cases include documents like invoices or scanned records, where the text is not machine-readable.
High-Performance Tools such as PyMuPDF (fitz) and PDFBox essentially do the same job as the libraries cited above; however, they run faster. This is particularly useful in enterprise environments or otherwise performance-sensitive settings.
Manipulation Libraries such as pikepdf provide additional functionality such as merging, splitting, rotating pages, and handling passwords. This makes it useful for pre-processing tasks before extracting the data with other tools. Some basic manipulation like splitting pages can be handled with other tools as well, though.
Finally, Query-Based Extraction is facilitated by tools like PDFQuery. This is a useful tool if you are only interested in specific data points from consistent sections within a larger PDF and can disregard the rest.
To summarize, if you’re dealing with simple text extraction, then PyPDF2, pdfminer.six, and Slate will be your friends. For more complex layouts with tables and images, pdfplumber or PyMuPDF will be the better choice. If you are only interested in tables, then you can get pretty far with tabula-py or camelot-py. Low-level PDF manipulation can be achieved with pikepdf and PDFBox. If you are only interested in specific sections of a PDF, try PDFQuery. And if you have to go back to basics and really work on image recognition, pdf2image and pytesseract are your allies.
Examples: Getting our hands on some sustainability-related and financial data
For a recent study, we needed to extract some public reporting data of steel producer ArcelorMittal. We started with the reporting year 2023 and used their ESG Fact Book as well as their annual report.
For our quantitative analysis, we were only interested in three pages of each document. For the ESG Fact Book, these were pages 28 to 30, which feature rich tables of sustainability data. For the annual report, these were pages 246, 248 and 250. We intended to extract all the tabular data to a series of CSV documents (comma-separated values, which can be easily reused with other data science tools in Python.)
ESG data
To extract the ESG data, we used tabula (for description, see section above). The code was indeed very simple and ran within a matter of seconds. We got some very clean and accurate CSV files from this. The code is the following:
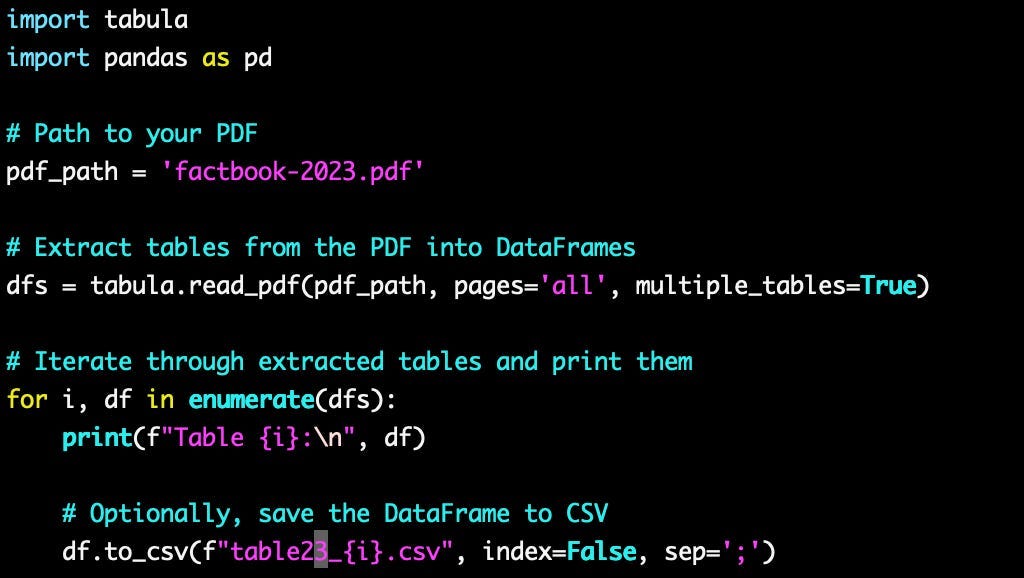
Financial data
The financial document was trickier. We tried several packages, including tabula, pdfplumber, camelot, and fitz, and ran into problems every time. The issue with the document seems to be that it has a non-standard encoding.
Unlike plain text files, PDFs are encoded in a way that preserves formatting, fonts, images, and layout across different devices. Text in a PDF might not be stored as raw text but as a set of instructions that define how characters should be displayed on the page, sometimes making it difficult to extract. PDFs can also contain different types of encoding for images, tables, and even fonts, which is why extracting data often requires specialized tools that can interpret these encoding structures. Sometimes, these encodings are non-standard, which makes this even trickier. Which was the case in the above document.
We therefore had to resort to a combination of pdf2image and pytesseract. The first package, pdf2image, is only used to make sure that the pdf can be read in properly and then get split into separate pages. The second package, pytesseract, is then used to recognize the letters on the page, line by line.
This was error-prone because the document has several greyed out areas, annotations, and other special features. Some fiddling about with the pixel resolution when reading it in, as well as with the Tesseract Page Segmentation Modes were needed to make sure that the tool was reading all characters properly. The outcome was a text file of the following fashion:
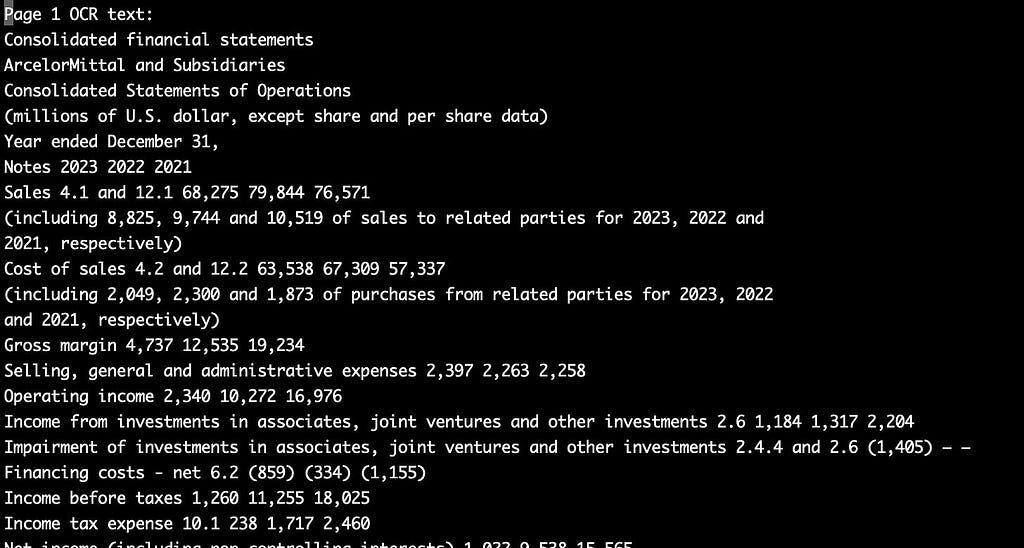
This needed to be cleaned up from superfluous lines and properly formatted. We custom-wrote a special script for this.
All in all, fiddling about with pdf2image and pytesseract took us a couple days’ work. Now, however, we have a code that will work with all kinds of atypically encoded PDF documents. It was therefore an investment into our future!
How Python stacks up against other languages and tools
Aside from Python, other tools come into consideration. These include R, Java, and manual extraction with Adobe Reader.
Python
First of all, if you are using Python already in your daily life, you might as well stick with it for PDF extraction tasks. It is easy to use, beginner-friendly, has a very rich ecosystem, and integrates with other super useful packages like pandas and numpy.
One downside of Python is that extracting data from PDFs with complex layouts or embedded images can be difficult, as we have seen above. Depending on the document structure, different Python libraries may handle PDFs with varying success, so some trial and error might be needed.
R
If you are a fan of R, you can in fact use it for PDF extraction. It provides similar packages to Python and they integrate well with R’s other data science tools. Also, it is particularly useful for tabular data. See for example the tabulizer package, which is similar to Python’s tabula-py.
That being said, its PDF handling tools are less numerous and less well developed, which can be a pain especially for more complex documents. Also, R is optimized for statistical analysis and can be slower than Python for generalist tasks like PDF extraction.
Java
Java is by far the most performant language on this list. It is compiled, so naturally it would run faster in most circumstances. In addition, Tabula and PDFBox are originally from Java — you might as well use the O.G., one might assume.
The big downside to this is that Java requires more boilerplate code and setup compared to Python. Setting up a Java environment and managing dependencies like PDFBox can be incredibly cumbersome for simple extraction tasks. In addition, the Java community around is not as vast or as beginner-friendly as Python’s.
Generally speaking, Java is therefore for the advanced practitioner. In enterprise applications, where performance and scalability are crucial because a task involves extracting data from thousands of PDFs or more in an automated system, Java might be a better choice. For most purposes, including ours at our startup Wangari, Python is the better choice though because it is much easier to get up-and-running with it.
The bottom line: A huge time-saver, but not a 100% automation
Extracting data from PDFs can be a huge bottleneck. We speak from experience. Our recent ventures into the PDF tools of Python have brought us 90 to 95 percent time savings on a task that once cost us a whole day’s work per company analyzed.
This is not the whole work though. We manually searched for the documents we needed, and then pre-processed them by using a copy where only the few relevant pages (out of a few hundred!) figured. In the future, we might build a web scraper and a page selector to make this task even faster.
We are interested in historical data, too, which means that extracting data of the reports of only 2023 (as we did in the examples above) will not be enough. We therefore need to write more code to take all the extracted data of several years and merge it into one. This is not trivial because data column descriptions can vary from one year to another, even in fairly standardized financial documents. We will cover this in an upcoming article.
Finally, once one has constructed a big CSV, one can analyse the results using statistical algorithms. We will talk about this in upcoming articles, too.
Originally published at https://wangari.substack.com.
Python Might Be Your Best PDF Data Extractor was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/UAsCy4l
via IFTTT


