
Another Hike Up Everest
How to make progress on hard problems in AI
New technology is born, matured, and eventually replaced. AI is no different and will follow this curve. Many news articles are already proclaiming that Generative AI (Gen AI) has arrived at the Trough of Disillusionment: the point in adoption where the early adopters are realizing the promises of the new technology are much more difficult to achieve than they realized.
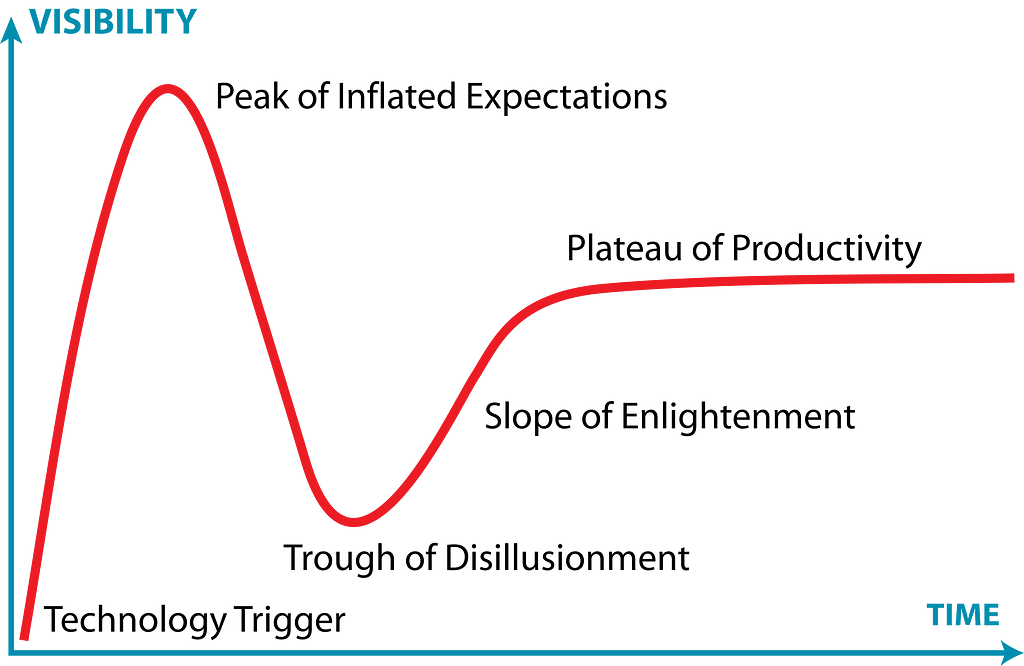
This is normal and has happened many times before Gen AI. Consider the boom and bust of blockchain — the lettuce you buy in stores will be tracked from farm to table with blockchain! Or Big Data: you’ll be able to know everything about your customer, delivering value to them and profits to you with little effort!
The trouble is that these problems being solved by each of these new technologies are actually quite vast. Each is its own Everest.
And just like Everest, you can’t hike up it in a day. Months or even years of preparation are required. Each camp on the way up is specialized for that location. Sometimes even the best prepared attempts fail to summit the mountain — that doesn’t always mean the team of climbers wasn’t qualified or capable: perhaps the weather was bad or they simply took the wrong route.
Your Gen AI strategy should be the same as your strategy for climbing Mount Everest (maybe hold off on the extra oxygen, though).
Each problem that Gen AI is being used to solve is typically a Big Hairy Problem — complicated inputs and complicated outputs with complicated processes connecting the two.
Remember: big leaps are dangerous when climbing mountains. Progress is actually made with small gradual steps along a path.

Every small step to the summit is preceded by the collection and organization of the materials needed on the mountain’s face. You do not want to be half way up Everest with no food or water left.
Similarly, you need to train yourself and your team to be physically able to perform at higher altitude in treacherous conditions.
Understand the Problem being solved
This shouldn’t mean “what does the solution look like today”. Modernization efforts often require replacing existing solutions built on workarounds and concessions. It’s critical to understand what the actual problem is. Where is the value from the outcome of the process actually being derived? How is it making a customer’s experience better? Clearly defining the problem helps later when defining clear requirements.
It’s critical to remember that humans are VERY GOOD at dealing with ambiguous requirements. As a result, many of the Big Hairy Problems that AI is solving are described like this:
“We’d like to use AI automate the complicated order system that we use to process all our large customers’ orders!”
Sounds awesome! Can you describe how that process works from end-to-end?
“Well, we get the email from the customer, extract the order information, and put that information into our order form. Then we upload that form into the order system for processing. Gen AI can automate that whole process, right??”
If we build it step-by-step, sure!
There’s a lot of ambiguity contained within the process above. Expecting a Gen AI process to be able to handle each nuance of the process above with little effort is a mistake.
- What formats do the emails come in? Is it always the same format?
- How is the order information described by the customer? Do they use colloquial terms for things? Or are do they use your item numbers?
- Is the order information from the customer the same that your fulfillment system uses? Is there a lookup that happens?
- What format is the upload expecting? Text? PDF? Excel?
- If it’s an Excel template, are there multiple sheets? Unwritable cells? Data validation requirements?
Gen AI can handle all of these tasks — you just have to be able to define each step along the way clearly. If you can’t clearly describe the input and output of a process, it’s likely that Gen AI will not do exactly what you’re expecting it to do.
If you approach this with a top-down perspective (the prompt would be “you’re an AI agent filling out order forms”), you’ll end up with a process that gets things right 50% of the time (honestly, still pretty good!) and not in the format you’re expecting. The issue is that for you’ll still need a human to review EACH output anyways which doubles the work.
The MVP: haven’t we been here before?
This is nothing new. We’ve been building Minimum Viable Products (MVPs) for years now. You must start small, solve a single step in the problem, and build bigger from there (with feedback from your customers!). AI products and workflows are no different. Build what is immediately useful and then expand from there.
How might we apply that to the order system described above? We should break each step in the process down and apply Gen AI where it makes the most sense:
- Customer sends an order email (unstructured inputs)
- Order details are put into a form (structured inputs)
- Form is formatted and uploaded into the system (structured outputs) OR:
- There is no form, and the order is constructed manually (unstructured outputs)
The content of emails are notoriously unstructured which makes the application of AI here a great use case! In this situation, ask your process owner “What must a valid email order contain?” Data like customer name, account number, address, items requested along with item quantity are good candidates. To maximize your Gen AI system’s accuracy and resiliency when handling these orders, define data structures that the AI should adhere to. I’ll use pydantic to help build these structures below:
from pydantic import BaseModel
class OrderItem(BaseModel):
ItemName: str
ItemQuantity: int
class EmailOrder(BaseModel):
CustomerName: str
AccountNumber: str
ShippingAddress: str
Items: list[OrderItem]
From here, we can use these objects to start giving structure to our AI:
>>> i = OrderItem(ItemName='eggs', ItemQuantity=2)
>>> i
OrderItem(ItemName='eggs', ItemQuantity=2)
>>> i.model_dump_json()
'{"ItemName":"eggs","ItemQuantity":2}'
>>> e = EmailOrder(CustomerName="James", AccountNumber="1234", ShippingAddress="1234 Bayberry Ln", Items=[i])
>>> e.model_dump_json()
'{"CustomerName":"James","AccountNumber":"1234","ShippingAddress":"1234 Bayberry Ln","Items":[{"ItemName":"eggs","ItemQuantity":2}]}'
Now with these examples you can give your Gen AI using few-shot prompting and increase accuracy. We’ll use LangChain OutputParsers to do some of the heavy lifting:
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-instruct")
template = """
{format_instructions}
<email>
{email_body}
</email>
Instructions:
- Read the email and extract the information in it.
- Respond in the format instructions given above.
Begin!
"""
parser = JsonOutputParser(pydantic_object=EmailOrder)
prompt = PromptTemplate(
template=template,
input_variables=["email_body"],
partial_variables={
"format_instructions": parser.get_format_instructions
},
)
chain = prompt | llm | parser
email_body = "hello i'd like to order 2 eggs. My name is James. My account number is 1234. My address is 1234 Bayberry Ln. Appreciate it!"
chain.invoke({"email_body": email_body})
The actual prompt being sent to OpenAI in this case is:
prompt = """The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
```{"$defs": {"OrderItem": {"properties": {"ItemName": {"title": "Itemname", "type": "string"}, "ItemQuantity": {"title": "Itemquantity", "type": "integer"}}, "required": ["ItemName", "ItemQuantity"], "title": "OrderItem", "type": "object"}}, "properties": {"CustomerName": {"title": "Customername", "type": "string"}, "AccountNumber": {"title": "Accountnumber", "type": "string"}, "ShippingAddress": {"title": "Shippingaddress", "type": "string"}, "Items": {"items": {"$ref": "#/$defs/OrderItem"}, "title": "Items", "type": "array"}}, "required": ["CustomerName", "AccountNumber", "ShippingAddress", "Items"]}```
<email>
"hello i'd like to order 2 eggs. My name is James. My account number is 1234. My address is 1234 Bayberry Ln. Appreciate it!"
</email>
Instructions:
- Read the email and extract the information in it.
- Respond in the format instructions given above.
Begin!"""
When you send that prompt, the LLM follows the example and extracts the information for you:
{
"CustomerName": "James",
"AccountNumber": "1234",
"ShippingAddress": "1234 Bayberry Ln",
"Items": [
{
"ItemName": "eggs",
"ItemQuantity": 2
}
]
}
By using this well-defined format for an email order, we can pass this parsed object back through the LLM and ask it to ensure that all the required fields for an order are present. If it’s not, we can route the email to a human for help!
For example, let’s suppose that all EmailOrders need a CompanyName field as well. If the validation is this straightforward, we can simply use pydantic validations (no AI needed!). If your use case gets more complicated, the output can be passed through an LLM to provide some higher level logic.
We’ll take the same order as above but leave out the CompanyName:
>>> class EmailOrder(BaseModel):
... CustomerName: str
... AccountNumber: str
... ShippingAddress: str
... Items: list[OrderItem]
... CompanyName: str
...
>>> e = EmailOrder(CustomerName="James", AccountNumber="1234", ShippingAddress="1234 Bayberry Ln", Items=[i])
Traceback (most recent call last):
File "<python-input-19>", line 1, in <module>
e = EmailOrder(CustomerName="James", AccountNumber="1234", ShippingAddress="1234 Bayberry Ln", Items=[i])
File "/Users/jbarney/.venv/lib/python3.13/site-packages/pydantic/main.py", line 212, in __init__
validated_self = self.__pydantic_validator__.validate_python(data, self_instance=self)
pydantic_core._pydantic_core.ValidationError: 1 validation error for EmailOrder
CompanyName
Field required [type=missing, input_value={'CustomerName': 'James',...ello', ItemQuantity=2)]}, input_type=dict]
Pydantic does a lot for us here by throwing a ValidationError. Our driver program can simply catch this error and funnel the email to a human reviewer.
Of course, an LLM can also detect this error. I’m showing this for completeness; typically you’ll want to leverage traditional programming for data validation:
prompt = """Evaluate that the input object matches the expected schema:
{input}
{schema}
Reply with "True" if it does match and "False" if it does not match.
"""
With all this in place, we now have a system that can easily handle properly written email orders. More importantly, we have implemented a self-governing process that keeps humans in the loop when the AI needs help.
Crucially, we didn’t rewrite the entire order entry process! We’ve taken a time-consuming part of the process and built a system that concentrates human effort in the areas where it makes the largest difference. Going forward, we can start modifying the other parts of the process, systematically removing the human toil.
Summiting Everest
This iterative approach to solving complicated problems is nothing new. All big problems need to be broken down into their constituent parts in order to truly be solved.
The “magic” of AI is particularly convincing, however. It’s easy to hope to make big leaps, given how capable these models are with just a few lines of input. Compared to technology like blockchain and Big Data, the effort required to go from idea to tantalizing proof-of-concept is minimal. AI doesn’t need dozens of custom configured servers to run a Map-Reduce job across 18 TB of data that took you 6 months to migrate.
So keep that simplicity in mind as you build your next AI solution: small steps to the summit.
See you up there!
Another Hike Up Everest was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from AI in Towards Data Science on Medium https://ift.tt/pTISn25
via IFTTT



{kind=link}
{kind=link}