
Decoding One-Hot Encoding: A Beginner’s Guide to Categorical Data
Learning to transform categorical data into a format that a machine learning model can understand
Introduction
When studying machine learning, it is essential to understand the inner workings of the most basic algorithms. Doing so helps in understanding how algorithms operate in popular libraries and frameworks, how to debug them, choose better hyperparameters more easily, and determine which algorithm is best suited for a given problem.
While algorithms are at the core of machine learning, they cannot produce effective results without high-quality data. Since data can be a scarce resource in some problems, it is crucial to learn how to preprocess it effectively to extract maximum value. Moreover, improperly preprocessed data can deteriorate an algorithm’s performance.
In this article, we will examine one-hot encoding, one of the most fundamental techniques used for data preprocessing. To do this effectively, we will first understand the motivation behind data encoding in general and then explore its principles and implementation in Pandas.
Problem
Let us imagine that we want to use a machine learning model on a given dataset. The dataset contains several features, one of which is categorical. Like most machine learning algorithms, our model requires a numerical vector as input. Based on this input, the model generates a prediction, calculates a loss value, and updates the model weights accordingly.
When dealing with a categorical feature, how can we pass this information to a model that operates only with numerical data? A naive approach is to map each unique category of the feature to an integer and pass that integer to the model. Despite the simplicity of this method, it has a major disadvantage that will be discussed in the example below.
Example
Let’s say we have a dataset where each row describes students. Specifically, there is a column representing the type of sport that students practice in their free time.

The naive encoding method described above would result in the following column:
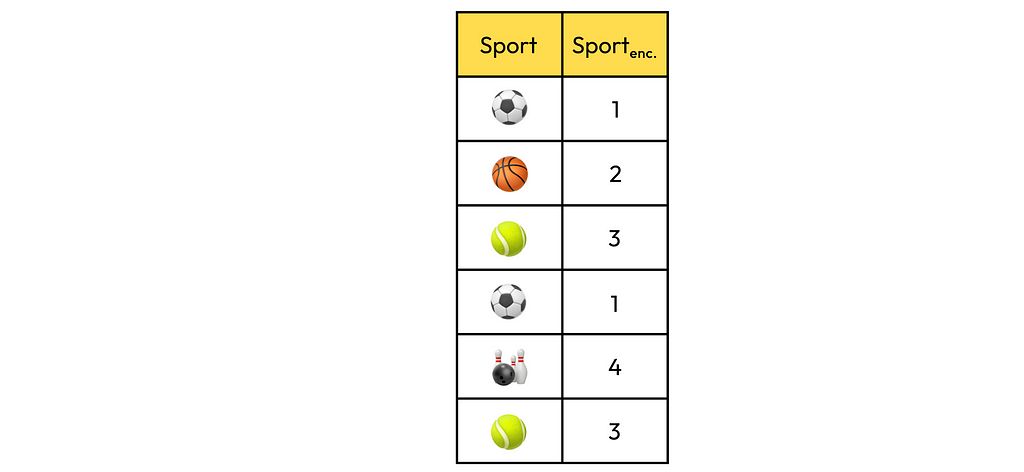
In this example, we see that soccer corresponds to 1, basketball to 2, and bowling to 4. Based on these values, would it be reasonable to say that bowling is, in some sense, “greater” than basketball, and basketball is “greater” than soccer? Probably not. In most cases, this wouldn’t make sense. However, this is exactly how the model interprets these values during training, as it cannot capture any semantic meaning between the encoded numbers.
Furthermore, based on these numerical values, the model may interpret the difference between bowling and basketball (4–2 = 2) as twice the difference between basketball and soccer (2–1 = 1). Clearly, we do not want the model to operate with this unintended logic.
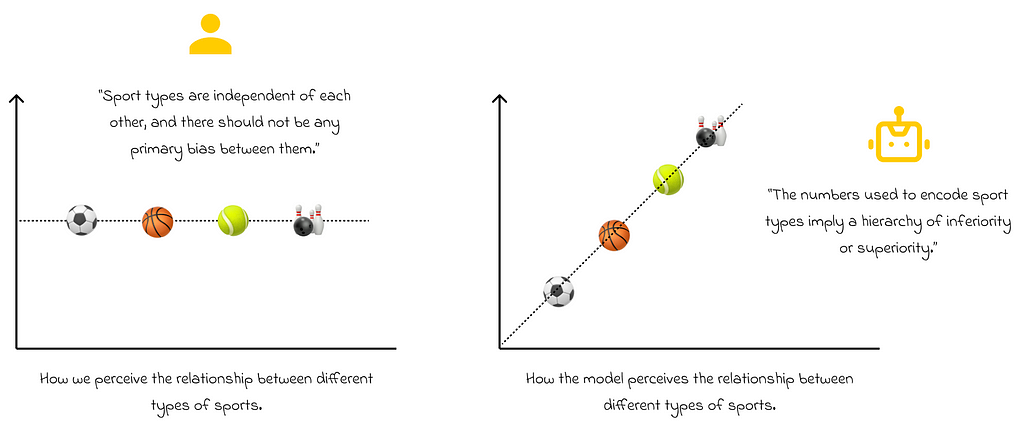
As a result, we can see that direct encoding will not positively impact the model’s performance.
Nevertheless, in some cases, this kind of direct encoding can still be useful. For example, if we wanted to rank types of sports based on their popularity or another factor, then it would be appropriate.
One-hot encoding
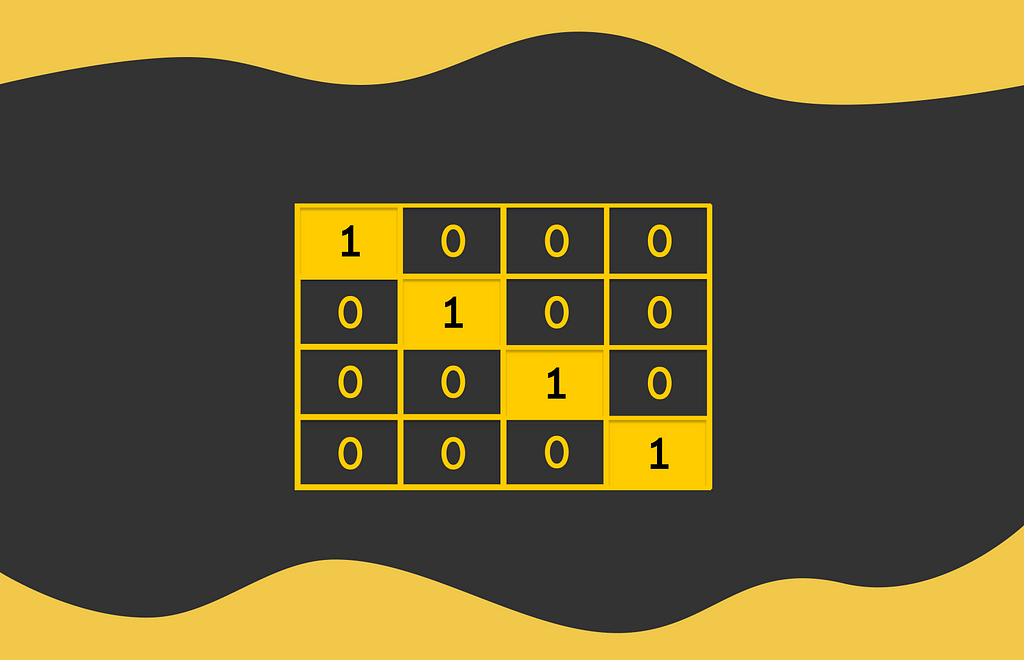
There are many encoding techniques for categorical features, but the one we will focus on is called one-hot encoding. This technique derives its name from the concept of a one-hot vector, which is a vector in which all components are 0 except for one component that has a value of 1.
To encode a categorical feature with n unique values, one-hot encoding uses vectors of dimension n, with each unique value mapped to a specific position where the 1 appears in the vector.
Returning to our example, the encoded sports feature would be represented by a vector of length 4 (if there are 4 unique types of sports).
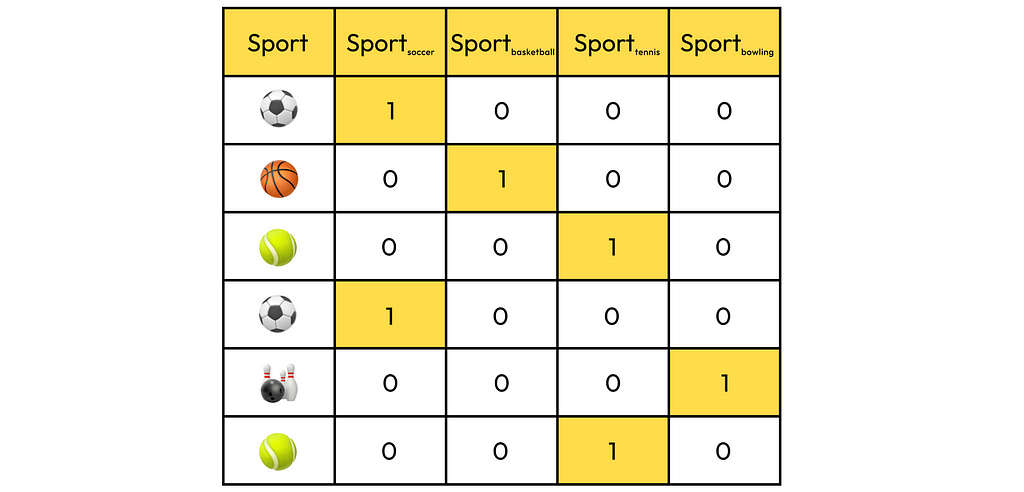
The i-th component of a one-hot vector can be viewed as a binary feature, answering the question of whether the object belongs to the i-th class of the encoded category (1) or not (0).
By having only two unique values in each encoded column, these values can now be semantically compared in a way that is easily interpretable by the model.
One-hot target
One-hot encoding is not only used for encoding categorical features, but it can also be applied to transform categorical targets. For example, if you want to predict an animal type, you can map each animal in the target column to its corresponding one-hot vector.
The only nuance is that now your model will need to learn to predict n values instead of just one. However, this is not a problem, as the predicted values can be normalized so that they sum to 1, and can ultimately be interpreted as probabilities that the object belongs to the i-th class. In this case, the loss function must also be adjusted, as its input will consist of a pair of vectors: the predicted vector and the true one-hot vector.

Implementation
The implementation of one-hot encoding is straightforward and involves mapping each category to a position of 1 in the one-hot vector.
To encode a categorical feature in Pandas, you can use the get_dummies() method.
import pandas as pd
columns = ['age', 'grade', 'languages', 'publications', 'sport']
data = [
(22, 86, 3, 17, 'soccer'),
(21, 77, 2, 10, 'basketball'),
(22, 90, 1, 14, 'tennis'),
(19, 82, 2, 8, 'soccer'),
(20, 94, 1, 13, 'bowling'),
(23, 71, 4, 7, 'tennis')
]
df = pd.DataFrame(data, columns=columns)
The code snippet above produces the dataframe that was shown at the beginning of this article. Now, with just a single line of code, we can apply the one-hot transformation and remove the original sport column:
df_encoded = pd.get_dummies(df, columns=['sport'], dtype=int)
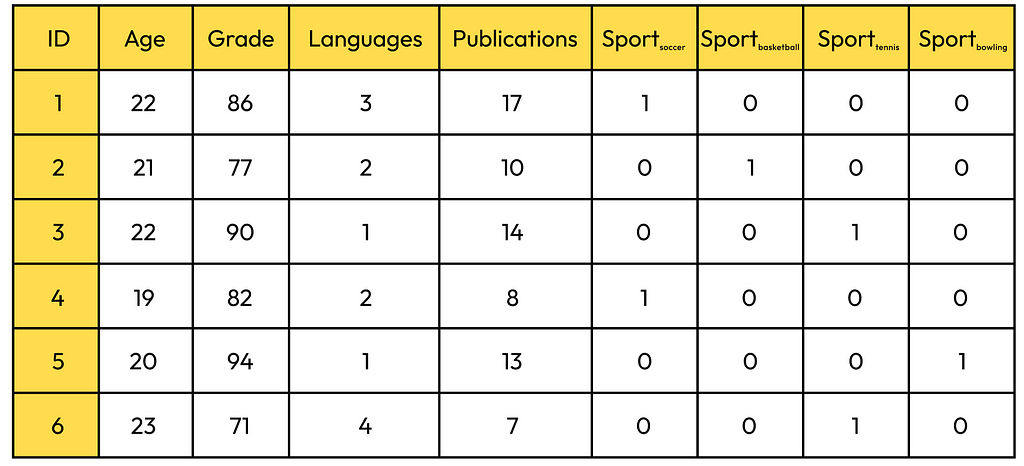
Even the name of the Pandas method get_dummies() suggests how simple and straightforward the one-hot encoding process is. 😄
Conclusion
In this article, we have explored one-hot encoding — the simplest algorithm in machine learning for encoding categorical data. For simple problems, it is quick and easy to implement in most data analysis libraries.
However, there may be situations where distinct category values have complex relationships with each other. In such cases, it is better to use more advanced approaches that consider additional feature information.
Finally, one-hot encoding is not recommended when a feature has many unique values. For instance, if a feature contains a thousand unique values, all of the one-hot vectors will have a dimensionality of 1000. Not only will this approach require a large amount of memory, but it will also be extremely slow when working with large datasets. To avoid the curse of dimensionality, it is better to consider other encoding methods in these cases.
Thank you for reading! If you enjoyed this article, be sure to check out my other articles on classical machine learning! ✍️
Conclusion
All images unless otherwise noted are by the author.
Decoding One-Hot Encoding: A Beginner’s Guide to Categorical Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/ivph8jg
via IFTTT


