
Machine Learning in Fraud Detection: A Primer
Balancing automation, accuracy, and customer experience in an ever-evolving adversarial landscape

Fraud detection is a cornerstone of modern e-commerce, yet it is also one of the least publicized domains in Machine Learning. That’s for a good reason: it’s an adversarial domain, where fraudsters constantly invent new ways to bypass existing models, and model developers constantly invent new ways to catch them.
The goal of fraud detection systems is to block fraudulent transactions, such as those placed by fake accounts using stolen credit cards, while at the same time preventing any friction to the shopping experience of genuine customers. False negatives (fraud transactions that mistakenly went through the system) result in monetary loss also known as ‘bad debt’ due to chargebacks initiated by the actual credit card owners, while false positives (genuine transactions that were blocked) result in poor customer experience and churn.
Consider that a modern e-commerce provider may process somewhere in the order of tens of Millions of orders per day, and that fraud rates are at the sub-percent level, and you’re starting to see why this is a challenging domain. It’s the ultimate needle-in-a-haystack problem, where the haystacks are overwhelmingly large and keep changing over time, and missing just a single needle can result in enormous monetary losses and a bad reputation.
At a high level, fraud detection systems need to optimize for three competing objectives at the same time,
- minimize bad debt due to false negatives,
- minimize account reinstatements due to false positives, and
- maximize automation.
Note that we can always solve for two of these by sacrificing the third: we could have 0 reinstatements and 100% automation while sacrificing bad debt by simply passing all orders. Or we could have 0 bad debt and 0 reinstatements while sacrificing automation by investigating all orders. Or we could have 0 bad debt and 100% automation while sacrificing reinstatements by canceling all orders.
The challenge in fraud detection is to find the optimal solution within the space spanned by these 3 extremes, using ML, high-quality labels and features, and vigorous operational management of rules, rulesets, and investigation backlogs.
Modeling approaches
One of the most common misconceptions about fraud detection is that it’s an anomaly detection problem. It’s not: fraud detection is a binary, supervised classification problem (whereas anomaly detection is unsupervised) that can usually be solved with standard classification models from logistic regression to gradient-boosted decision trees (GBDTs) and neural networks. GBDTs can be particularly useful for such problems because they tend to be best at handling skewed or heavy-tailed feature distributions and other forms of dataset irregularities (McElfresh et al 2024).
In order to handle both the scale and the skew of the problem (Millions of orders per day with sub-percent fraud rates), a useful design choice is a funnel design, consisting of several stages of ML models with increasing complexity, trained on data with increasing fraud rates. Each stage could then make automated decisions such as “pass”, “block”, or “send to next stage”, depending on the model score of the ML model at that stage, with human investigation by fraud specialists being the final stage.
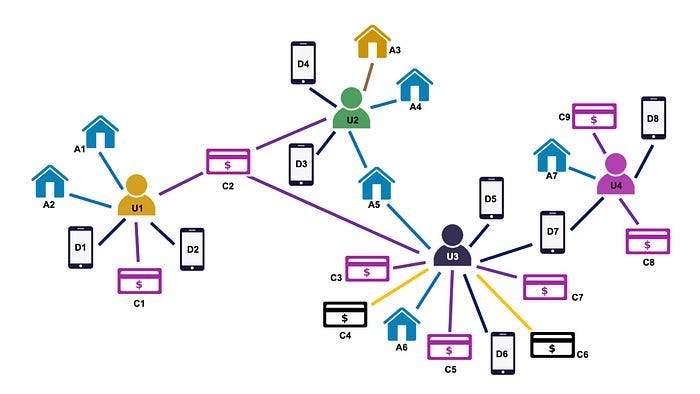
Graph Neural Networks (GNNs) are a popular choice in fraud detection models due to the graph-based nature of the data, as illustrated in the above figure. In a GNN, data is represented as a graph where the nodes are entities (such as users, devices, payment instruments, or shipping addresses) and the edges represent relationships (such as shared IP address, shared shipping address, shared payment method, shared device, etc.). During model training, the GNN updates the representations for each node in the graph by aggregating information from their connected neighbors, allowing it to learn from any relationship patterns that exist in the data. Ultimately, the GNN outputs a classification score for each node in the graph, which corresponds to “fraud probability” for that node. Examples for such systems are BRIGHT, NGS, and H2F.
Relatively recently, and motivated by the success of LLMs, user action sequence models have become popular in fraud detection as well. The key idea is to have a sequence model learn both the normal patterns inherent in genuine user behavior as well as the abnormal patterns in the behavior of fake accounts. Examples for such systems are HEN, Interleaved Sequence RNN, and BERT4ETH.
Labels and features
Labels for training the models can come from chargebacks (false negatives), reinstatements (false positives), and investigator decisions, where each of these sources has its own pros and cons.
For example, chargebacks are by far the best source of positive labels as they indicate fraud cases that the model missed before, but they’re also delayed: it may take several weeks or even months for the credit card owner to notice the fraudulent charge. In some cases, a fraudulent transaction may never be discovered by the credit card owner, resulting in “silent” false negatives. Similarly, reinstatements are an extremely useful signal for false positives, however some customers may simply not bother to complain and shop elsewhere, resulting in silent false positives. Investigator decisions may be the best source of ground truth however also the most expensive.
Features can come from various sources, including
- product-related features, such as price, product category, or brand,
- accouunt-related features, such as account age, geographical location, IP address, or features summarizing shopping history,
- risk tables, which are categorical features (zip code, billing country, credit card issuer, etc) encoded such that each category is being mapped to the average fraud rate for that category (Micci-Barreca 2001),
- graph-based features, such as whether the IP address, geographical location, or product is linked to any known fraudulent activity in the past.
Feature engineering is one of the most important tools used to improve fraud models. Oftentimes, a new fraud pattern can only be stopped by the introduction of a new set of features that makes the model sensitive to that new pattern. However, features also tend to lose their efficacy over time, as fraudsters find new ways to bypass the model. This does not mean that one can deprecate old features, as this would re-introduce old vulnerabilities. Ideally, the model should be able to draw from a large pool of features with constantly changing importances. This is where the greedy nature of GBDTs can be extremely useful.
Rules and rulesets
Rulesets may be not the first thing that comes to mind when talking about Machine Learning applications: ML, after all, is supposed to be a way to replace hand-crafted rules. However, rules are really where the “rubber hits the road” as they translate model scores into automated actions. A rule in this context has the form “IF condition THEN action”, such as
IF account_age_days<30 & model_score>0.95 THEN block_order
which would block orders from new accounts with model scores larger than 0.95. We could then estimate the performance of this block rule either measuring the ratio of reinstatements to overall rule volume (cheap but less accurate) or by queueing a fraction of the rule volume to investigators (expensive but more accurate).
0.95 in this case is the decision threshold, and it needs to be carefully tuned on historic data. Ideally, the scores should be risk-calibrated, that is, a score of 0.95 corresponds to a 95% probability that the order is indeed fraudulent. In practice however, it is very difficult to achieve such a perfect calibration because the fraud patterns are constantly shifting. Once the model has been calibrated on historic data, it may already be mis-calibrated with respect to production data. For this reason, tuning rule thresholds is one of the most important but also one of the most operationally demanding tasks in fraud detection systems.
Instead of thresholding on account age, it may also make sense to threshold on dollar-amount so that we can be more conservative if there’s more money at stake:
IF item_price_dollar>1000 & model_score>0.5 THEN investigate
and so on.
In practice, we’ll need a ruleset consisting of multiple such rules for different conditions that we need to take into account. One of the operational challenges in fraud detection is that these rulesets tend to increase in complexity over time, as new rules need to be added for new edge cases. At the same time, rules that once worked well may degrade over time simply because the fraud patterns changed or because new rules have been added. This ruleset debt, when poorly managed, can result in an enormous operational workload just to “keep the lights on”.
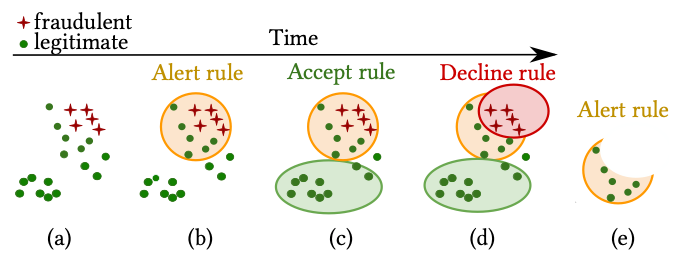
Automated ruleset management systems have therefore become a useful innovation in the domain. One example is Feedzai’s ARMS (Aparício et al 2020), which automatically optimizes a ruleset using a combination of random search, greedy expansion, and genetic programming. In experiments with actual fraud detection rulesets, the authors were able to automatically reduce ruleset size by 50–80% without loss of overall ruleset performance. In similar work, Gianini et al 2019 were able to reduce the number of rules in a fraud detection ruleset by 90% by interpreting the rules as players in a game and using Shapley values to estimate their relative contributions, an approach inspired from Game Theory.
Backlog management

Along with ruleset management, backlog management is one of the key operational tasks inherent to fraud detection systems. The backlog here is simply the queue of all orders that need to be investigated. You can think of it like a bathtub, where the rule volume for our “investigate” rules determine how much is flowing in and the number of investigators determine how much is flowing out. The task then is to make sure that that we never pour more into the bathtub than what is flowing out.
As a concrete example, let’s say we have a pool of 50 investigators working around the clock and a single investigation takes on average 30 minutes, resulting in an average throughput of 100 investigations per hour. This means that if we manage to keep the backlog below 100 orders at all times, then a genuine customer will never have to wait for more than one hour for their order to through the system. If the backlog starts to get larger than the wait times we’d like to allow, we need to intervene by releasing some of the backlog using heuristic adhoc rules while at the same time tuning the ruleset such as to reduce the inflow into the backlog.
Coda: A highly operational ML discipline
It should have become clear from this brief overview that fraud detection is an ML discipline that is very much operationally driven. It is extremely important to closely monitor model performance, rule performance, ruleset performance, investigation backlog, chargebacks and reinstatements, and pick up early on any warning signs on any of these indicators. A single missed “needle in the haystack” could result in considerable monetary loss and reputation damage.
As technology advances, the landscape of fraud detection will continue to evolve, bringing new tools and methodologies to the forefront, including the integration of reinforcement learning for more automation of operational tasks such as ruleset management, LLMs for incorporating unstructured data such as customer communications, or generative models for creation of synthetic fraud patterns to help in model training. However, the success of these systems will ultimately hinge on vigilant operational management.
Machine Learning in Fraud Detection: A Primer was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/slcNkoe
via IFTTT


