
Introducing the New Anthropic PDF Processing API

Anthropic Claude 3.5 now understands PDF input
In the last few weeks, Anthropic has released some exciting beta features that have largely gone under the radar. One of these was its new token-counting API. I have already written an article on this, which you can read by clicking the link below.
Introducing the New Anthropic Token Counting API
The other exciting feature, and the subject of this article, is that Claude 3.5 can now process PDFs and understand both text and visual content within PDF documents.
PDF Capabilities
Claude works with any standard PDF file, allowing you to inquire about text, images, charts, and tables within your documents. Here are some common use cases:
- Analyzing financial reports, interpreting charts and tables
- Extracting key information from legal documents
- Assisting with document translations
- Converting document content into structured formats
Limitations
Because this is still a Beta release, there are a few limitations to its use. Right now, it can handle a maximum file size of 32MB, and the number of pages in any one document is limited to 100.
Supported Platforms and Models
PDF support is currently available on the latest Claude 3.5 Sonnet model (claude-3-5-sonnet-20241022) through direct API access.
Calculate Expected Token Usage
The token count for a PDF file is determined by the amount of text extracted and the total number of pages. Each page is converted to an image, and token costs are calculated accordingly. Depending on content density, each page typically requires between 1,500 and 3,000 tokens.
Standard input token pricing applies, with no extra fees for PDF processing.
You can also use token counting (see story link above) to calculate the number of tokens for a message that includes PDFs.
Okay, let’s get started. First, I’m developing using Windows WSL2 Ubuntu. If you’re a Windows user, I have a comprehensive guide on installing WSL2, which you can find here.
Setting up a dev environment
Before we start coding, let’s set up a separate development environment. That way, all our projects will be siloed and won’t interfere with each other. I use conda for this, but use whichever tool you’re familiar with.
(base) $ conda create -n claude_pdf python=3.10 -y
(base) $ conda activate claude_pdf
# Install required Libraries
(claude_pdf) pip install anthropic jupyter
Getting an Anthropic API key
You'll need an Anthropic API key if you don’t already have one. You can get that from the Anthropic Console. Register or Sign-In, then you’ll see a screen like this,
Click the Get API Keys button and follow the instructions from there. Take note of your key and set the environment variable ANTHROPIC_API_KEY to it.
The code
For my input PDF, I’ll use a copy of Tesla’s Q10 September 2023 quarterly submission to the Securities and Exchange Commission that I downloaded to my local PC.
This document is 51 pages of mixed text and tabular data. You can see what it looks like online by clicking here.
Example 1 — Asking a basic question
“What is tesla’s phone number?”
import anthropic
import base64
# First fetch the file
with open("/mnt/d/tesla/tesla_q10_sept_23.pdf", "rb") as pdf_file:
pdf_data = base64.standard_b64encode(pdf_file.read()).decode("utf-8")
# Finally send the API request
client = anthropic.Anthropic()
message = client.beta.messages.create(
model="claude-3-5-sonnet-20241022",
betas=["pdfs-2024-09-25"],
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": pdf_data
}
},
{
"type": "text",
"text": "What is tesla's phone number?"
}
]
}
],
)
print(message.content)
It came back with this answer.
[BetaTextBlock(text="According to the document, Tesla's phone number
is (512) 516-8177. This is listed on the first page of the Form 10-Q as
their registrant's telephone number.", type='text')]
Not too shabby. It's an impressive start.
Example 2 — Let’s try a harder question.
What were the energy generation and storage sales for the Three Months Ended September 30 in 2022 and 2023 ?
If we look at the PDF, we can see that the answer to this is in a table on Page 10. The figures are 966 and 1416 million dollars, respectively.

message = client.beta.messages.create(
model="claude-3-5-sonnet-20241022",
betas=["pdfs-2024-09-25"],
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": pdf_data
}
},
{
"type": "text",
"text": "What were the energy generation and storage sales for the Three Months Ended September 30 in 2022 and 2023 ?"
}
]
}
],
)
print(message.content)
And the response from Claude.
[BetaTextBlock(text="According to the financial statements, Tesla's
energy generation and storage sales were:\n\n- Three months ended
September 30, 2023: $1,416 million\n-
Three months ended September 30, 2022: $966 million\n\n
This represents an increase of $450 million or approximately
47% year-over-year for that segment's sales revenue.", type='text')]
That’s fantastic. That is a spot-on answer again.
Example 3 — using prompt caching
For repeated analysis of a PDF, Anthropic recommends the use of prompt caching to reduce your token usage, hence costs. Prompt caching can be “switched on” by simply adding the following small changes in the message API code,
1/ Change
betas=["pdfs-2024-09-25"],
to
betas=["pdfs-2024-09-25", "prompt-caching-2024-07-31"],
2/ Add the following to the messages content section in the API call
...
"cache_control": {"type": "ephemeral"}
...
Now, when you run your RAG code, all the document contents will be cached, and subsequent calls to interrogate it will use the cached version, resulting in much much less tokens being used. According to the Anthropic documentation,
“The cache has a 5-minute lifetime, refreshed each time the cached content is used.”
Let’s see another full example and include the prompt caching code.
We are asking an old favourite question of mine, which I’ve used in previous articles on implementing RAG on Tesla’s Q10 PDF.
“What are the Total liabilities and Total assets for 2022 and 2023”
To a human, the answer is easy. Just go to page 4 of the PDF, and you’ll see this table,
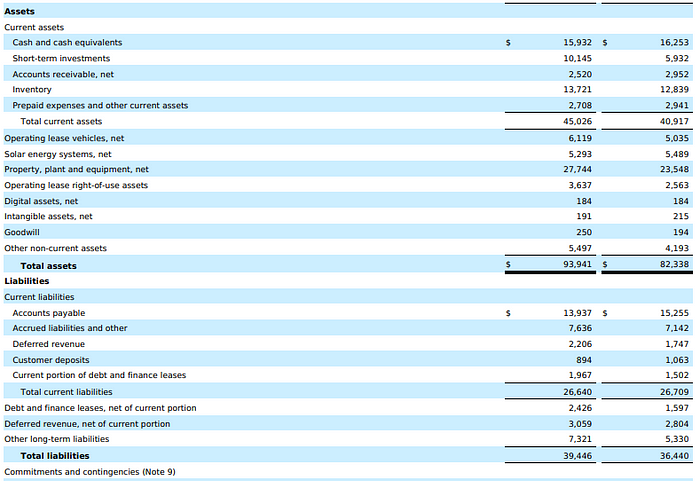
As you can see, the Total assets for 2022/2023 were (in Millions) $93,941 and $82,338. The Total liabilities were (in Millions) $39,446 and $36,440. Let’s see if Claude can answer this.
message = client.beta.messages.create(
model="claude-3-5-sonnet-20241022",
betas=["pdfs-2024-09-25", "prompt-caching-2024-07-31"],
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": pdf_data
},
"cache_control": {"type": "ephemeral"}
},
{
"type": "text",
"text": "“What are the Total liabilities and Total assets for 2022 and 2023”?"
}
]
}
],
)
print(message.content)
And the answer.
[BetaTextBlock(text='According to the consolidated balance sheets in the
document:\n\nFor September 30, 2023:\n- Total liabilities: $39,446 million\n-
Total assets: $93,941 million\n\nFor December 31, 2022:\n- Total liabilities:
$36,440 million \n- Total assets: $82,338 million', type='text')]
Spot on again.
Example 4— Interpreting diagrams/images
For my final example, I created a PDF, then pasted an image of an AWS architecture diagram into it, and saved it. Here is what it looks like.
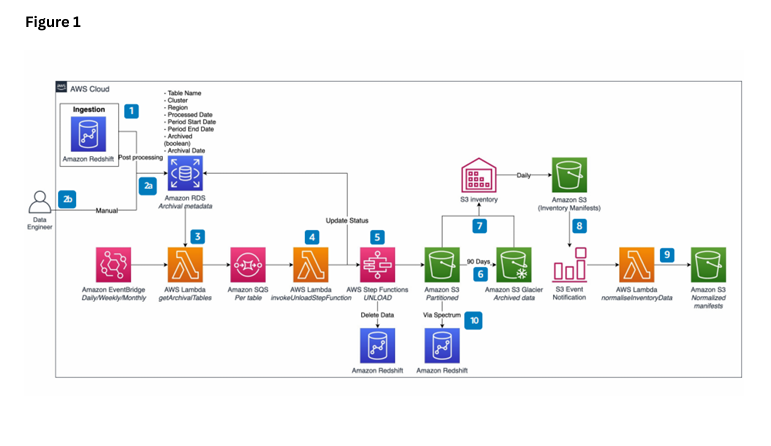
Let’s see if the model can interpret what it is.
import anthropic
import base64
# First fetch the file
with open("/mnt/d/images/arch.pdf", "rb") as pdf_file:
pdf_data = base64.standard_b64encode(pdf_file.read()).decode("utf-8")
# Send the API request
client = anthropic.Anthropic()
message = client.beta.messages.create(
model="claude-3-5-sonnet-20241022",
betas=["pdfs-2024-09-25"],
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": pdf_data
}
},
{
"type": "text",
"text": "What does the diagram depict"
}
]
}
],
)
for block in message.content:
print(block.text) # Print only the text attribute
The diagram (Figure 1) depicts an AWS Cloud architecture workflow for data
processing and inventory management. It shows:
1. An ingestion phase starting with Amazon Redshift
2. Post-processing steps using Amazon RDS for archival metadata
3. A series of AWS services working together including:
- Amazon EventBridge
- AWS Lambda functions
- Amazon S3
- AWS Step Functions
- S3 Inventory
- S3 Glacier
The workflow appears to handle data movement, processing, and storage with
various status updates and notifications. There's a daily inventory process
and both temporary and long-term storage solutions implemented through Amazon
S3 and S3 Glacier. The diagram shows how data flows through these different
AWS services and includes features for data deletion and archival management.
This seems to be a complete data pipeline architecture that handles ingestion,
processing, storage, and lifecycle management of data within the AWS ecosystem.
Another impressive response.
Summary
All I can say is that PDF processing using LLMs has come a long way in a short space of time. Claude’s PDF understanding is very impressive
Until recently, the last question I asked on the Tesla PDF about total liabilities and assets was almost impossible for AI and RAG models to answer correctly. I’ve tried several methods before, most recently by using Google’s Gemini Flash 1.5 model.
The only way I could get that model to answer correctly was by telling it which specific page of the PDF document to go to for the information.
Before that, I also tried using AWS Bedrock with a knowledge base and Claude V1.2 LLM. With that setup, I got close to the correct answer, but it was still not 100% right.
The only time I got the correct answer immediately was when I used LlamaParse.
The big difference between this version of Claude and a traditional RAG system like LlamaParse is its simplicity. There’s …
- No chunking.
- No vectorisation / Embedding
- No vector DB storage
- No similarity searching.
- No fuss.
I’ve said it before, and I’ll repeat it here: I believe traditional RAG processing is dead in the water for many, not all, use cases. What do you think?
To find out more about PDF processing with Anthropic, check out their documentation using this link.
Anyway, that’s all for me for now. Hopefully, you found this article useful. If you did, please check out my profile page at this link. From there, you can see my other published stories and subscribe to get notified when I post new content.
Times are tough and wallets constrained, but if you got real value from this article, please consider buying me a wee dram.
If you liked this content, I think you’ll also find these related articles interesting.
- Develop, then deploy a WEBP to PNG image converter Taipy App to the web — Part 1
- C Programming Using Claude’s New Computer Use Model
Introducing the New Anthropic PDF Processing API was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/JFhAgN9
via IFTTT


