
Saving Pandas DataFrames Efficiently and Quickly — Parquet vs Feather vs ORC vs CSV
Optimisation
Saving Pandas DataFrames Efficiently and Quickly — Parquet vs Feather vs ORC vs CSV
Speed, RAM, size, and convenience. Which storage method is best?
With the ever-increasing volume of data that is produced there is inevitably a need to store, and reload, that data efficiently and quickly.
CSV has been the go to staple for a long time. However, there are much better alternatives specifically designed to deal directly with the storage, and efficient re-loading, of tabular data.
So, how much are you losing out if you are still using CSV format for storage of your data tables? And which alternative should you consider?
Introduction
When it comes to storing tabular data the ideal would be:
- Fast to write
- Fast to read
- Low RAM usage
- Low storage requirements
- Good options for compression
An option to read only part of the data, without loading the whole dataset, would also be an excellent addition to the above.
The list outlined above will therefore form the base of testing some of the more widely used methods against these factors. Specifically:
- CSV
- Feather
- Parquet
- ORC
A Brief Outline of the Storage Methods
This section will give a rough overview of each of the storage methods that will be utilised throughout this article. A simple primer, nothing more.
CSV

CSV (Comma Separated Values) is probably (still!) one of the most widely used methods of storing tabular data.
As the name implies, each row is a list of values separated by commas. Each comma separator indicating a new column, and each new line indicating a new row. Very simple.
There is no easy way to read partial data, especially with regard to columns. So generally all data must be read to access even a small portion of the stored data.
Furthermore, although the name ‘comma’ separated values would imply a consistent standard, in reality this is not the case. Quite frequently semi-colons, tabs, and even plain spaces are used as the separator.
Not to mention potential inconsistencies in character encoding, and handing of a header row. All of which make the implementation of an efficient and repeatable encoding and decoding method more difficult.
Feather

…a portable file format for storing Arrow tables or data frames (from languages like Python or R) that utilizes the Arrow IPC format internally. Feather was created early in the Arrow project as a proof of concept for fast, language-agnostic data frame storage for Python (pandas) and R. There are two file format versions for Feather
-arrow.apache.org
Essentially a binary format that saves raw arrow data:
Apache Arrow defines a language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs. The Arrow memory format also supports zero-copy reads for lightning-fast data access without serialization overhead.
-arrow.apache.org
In essence it ticks a lot of boxes:
- Can read specific columns only (i.e. a columnar storage format)
- Multi-threading
- GPU usage
- Compression: zstd or lz4
Parquet

Apache Parquet is:
…an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides high performance compression and encoding schemes to handle complex data in bulk and is supported in many programming language and analytics tools.
-parquet.apache.org
It would be fair to say that Parquet is more ‘feature rich’ than Feather (I won’t go into detail here), and is generally used more extensively in Big Data. In a basic usage sense they are, however, pretty comparable.
- Can read specific columns only (i.e. a columnar storage format)
- Multi-threading
- GPU usage
- Compression: snappy, gzip, brotli, lz4 and zstd
ORC (Optimised Row Columnar)

This is an interesting one.
Released around the same time as Parquet back in 2013, ORC is another columnar based file format. It has been adopted by large institutions such as Facebook, and even has claims such as:
Facebook uses ORC to save tens of petabytes in their data warehouse and demonstrated that ORC is significantly faster than RC File or Parquet.
-orc.apache.org
Now, it should be noted that ORC is generally used with Hadoop and Hive, so in the more basic usage we will be covering here it will be interesting to see what happens in comparison to Parquet and feather.
- Can read specific columns only (i.e. a columnar storage format)
- Multi-threading
- GPU usage
- Compression: snappy, zlib, lz4 and zstd
The Plan
The plan is basically to make real world comparisons of these different storage methods using the Pandas library.
Main Comparison
The comparisons will be made on five factors:
- Final saved file size
- Speed of write
- Speed of read
- RAM used while reading
- RAM used while writing
This will be completed for all of the formats, and all compression methods available to that particular file format:
CSV — No compression, bz2, gzip, tar, xz, zip, zstd
Feather — No compression, lz4, zstd
Parquet — No compression, brotli, gzip, lz4, snappy, zstd
ORC — No compression, lz4, snappy, zlib, zstd
Note: all compression algorithms will be used at their default settings utilised by Pandas. There is the option to fine tune this in some cases, but it will not be covered in this article.
Additional investigation
Since the release of Pandas 2 it has been possible to use PyArrow data types in DataFrames, rather than the NumPy data types that were standard in version 1 of Pandas.
We will also find out whether the new PyArrow datatype available in Pandas 2.0 makes a difference…
Does this make a difference when it come to saving and reading data? We will find out.
The Data
Dummy data has been generated for the various tests. It is deliberately on the larger side of things, resulting in DataFrames that are around 2GB in size when saved as a plain CSV.
In addition, a mixture of data types will be investigated:
DataFrame 1 — Mixed (floats, strings and booleans)
100000 rows and 1200 columns
Uncompressed CSV — 2.27GB
400 columns of floats, strings and booleans, respectively
DataFrame 2— Floats only
100000 rows and 1200 columns
Uncompressed CSV — 2.18GB
Taken from a random uniform distribution between 0 and 100:
floats_array = np.random.default_rng().uniform(low=0,high=100,size=[rows,cols])
DataFrame 3— Strings only
100000 rows and 600 columns
Uncompressed CSV — 1.98GB
Strings are generated as an MD5 hash of the floats used for the floats array, with any “7” present replaced with a space.
Note: this DataFrame has half the columns of the previous DataFrames as strings take up more space. However, final file size is roughly the same.
string_array[:,i] = df_floats.iloc[:,i].apply(lambda x: hashlib.md5(str(x).encode('utf-8')).hexdigest().replace("7"," ")).to_numpy()
DataFrame 4— Booleans only
100000 rows and 6000 columns
Uncompressed CSV — 3.30GB
bool_array = np.random.choice(a=[False, True], size=(rows, cols))
Note: this DataFrame has significantly more columns than the previous DataFrames as booleans don’t take up a lot of space. Final file size is actually about 50% larger than previous DataFrames.
Testing Rig
Just for transparency, this is the setup on the computer that ran all the tests in this article:
CPU — Intel i7–4790K
RAM — 20GB (all tests stayed within RAM, no swap was utilised)
GPU — EVGA GeForce GTX 1070 FTW
SSD — WD SN850 1TB (NVMe)
OS — Arch Linux
This should give you a rough benchmark when looking at the results.
Testing — Mixed Data
Initially, the testing will be broad and show a comparison between all methods with a mixed dataset (floats + strings + booleans).
We will then drill down into more specific testing for the formats coming out on top in later sections.
Note: in general all RAM statistics and write/read times will have slight variation due to it being tested on a live system.
Specifically with regard to RAM, the results are generally reliable as I was able to monitor actual usage through system apps as a comparison. Any small or negative RAM usage values can essentially be treated as zero.
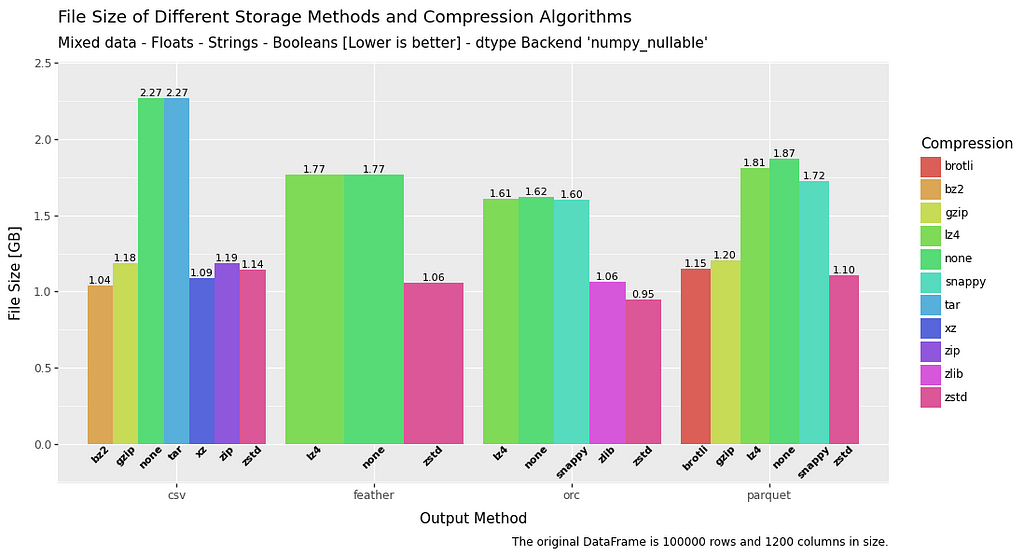
All Methods — File Size — Mixed Data
In terms of generated file sizes it would appear that all formats are relatively comparable if a compression method is used. However, it is clearly a significant advantage to use anything but CSV if you intend not to use any compression methods at all.
Let’s see whether read/write speeds and RAM usage change the picture.
All Methods —Execution Time — Mixed Data
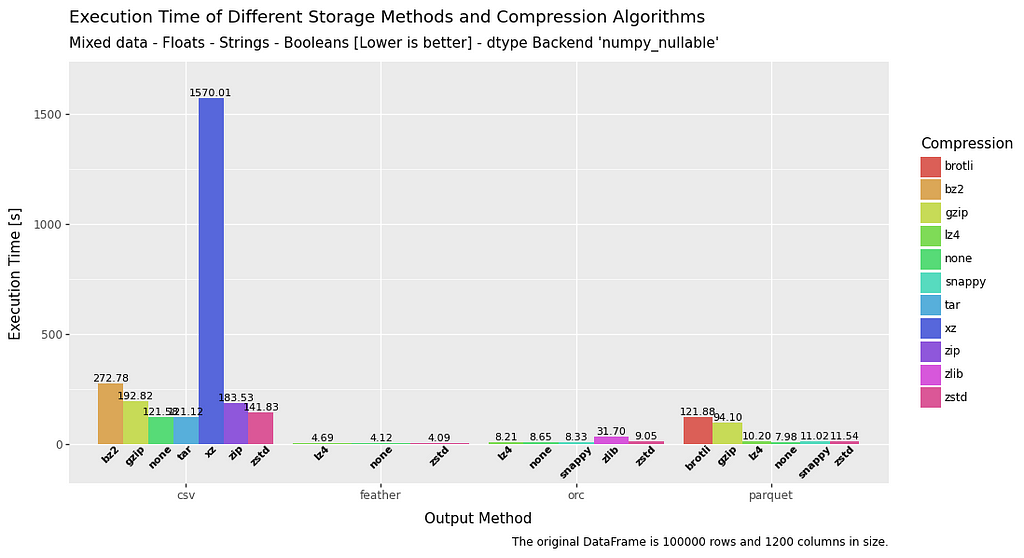
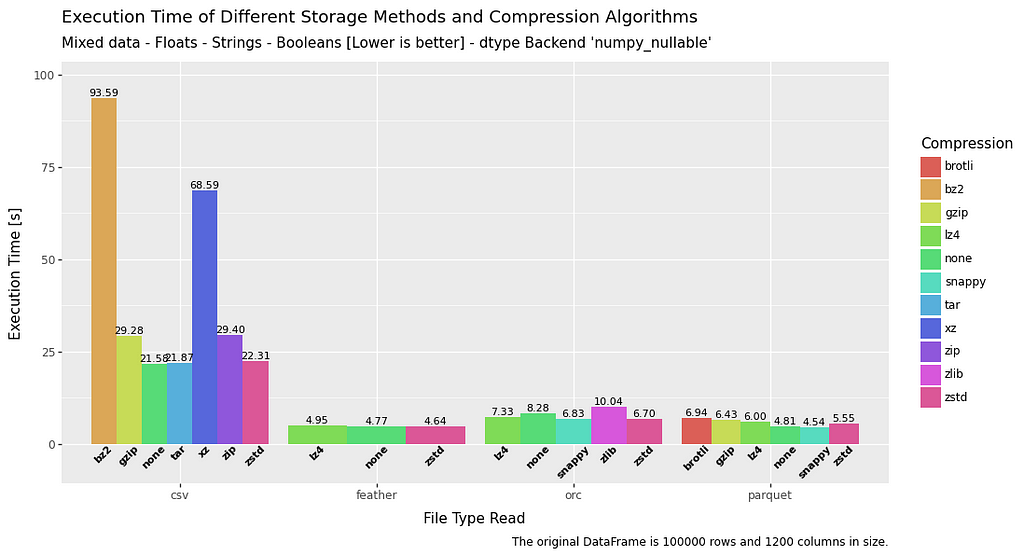
Execution time is where CSV really starts to show it’s inefficiencies. So much so that it is generally (excluding brotli and gzip from the parquet tests) at least four times slower to write, and at least twice as slow to read compared to all other methods, regardless of compression.
As briefly mentioned above, the brotli and gzip algorithms are also woefully slow when it comes to write speed.
All Methods — RAM Usage— Mixed Data
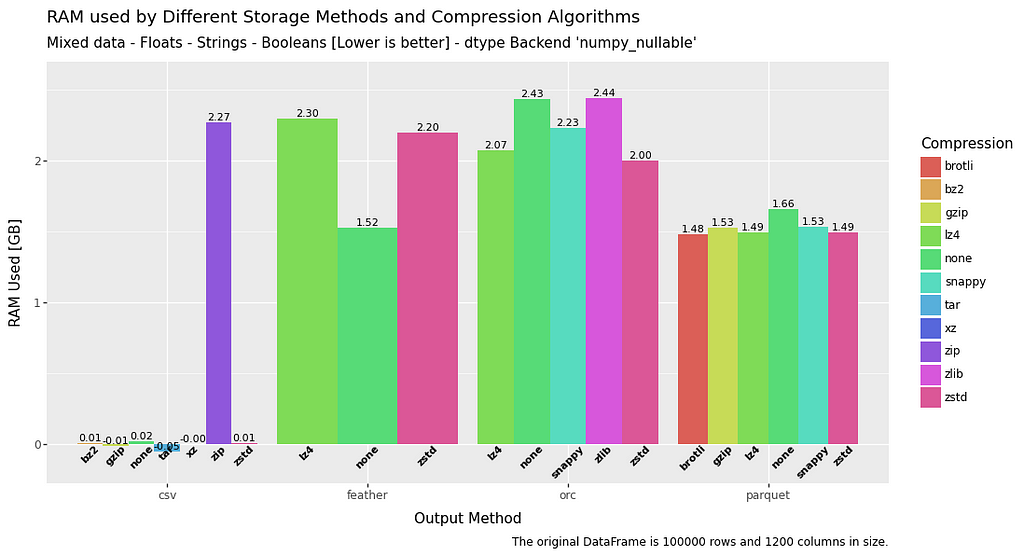
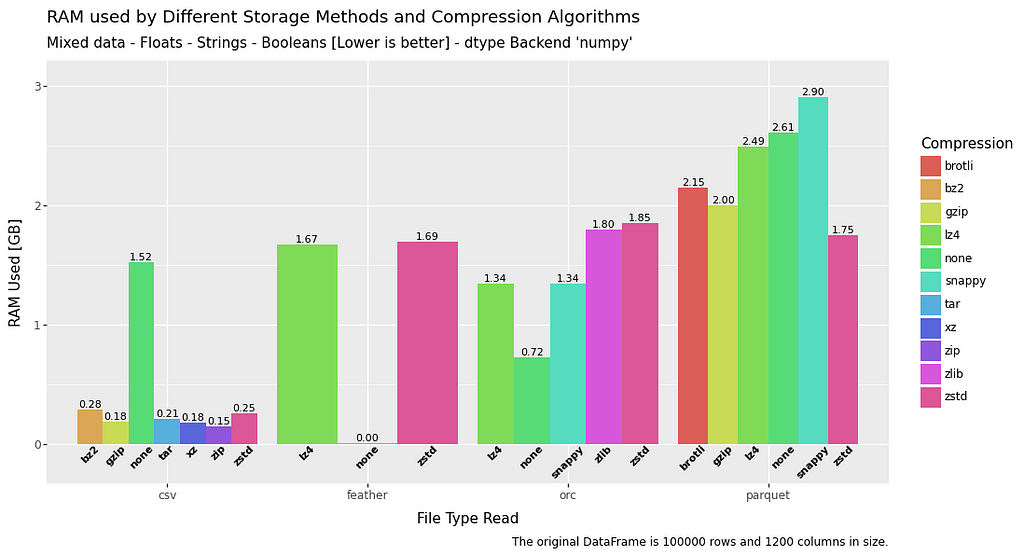
RAM usage is interesting. CSV performs very well. That is something to bear in mind if you have very stringent RAM requirements, and execution time is not an issue.
However, there are some notable results here. Uncompressed feather is a top performer in both read and write.
With compression, feather and orc perform at a similar level on both read and write. With parquet generally excelling at write, but in some circumstances over utilising RAM in read operations.
Mixed Data — Takeaway
Taking all factors together with regard to mixed data, there are actually some very interesting results.
CSV should be ignored
CSV makes little sense to use when compared to the other methods, mainly due to the extremely slow execution speed when compared to other methods.
The only exception is if you have very stringent RAM requirements.
ZSTD is the superior compression method
It is quite obvious from the results that ZSTD is the standout compression method regardless of the file type that is used.
No matter which metric you look at, it performs well. It has some of the highest compression ratios, whilst also executing quickly, and using a relatively small amount of RAM.
Moving on…
The next few sections will drill down the specifics a little more. CSV will also not feature, as I consider it out of the race at this point. It also makes the graphs clearer!
Specifically, the following will be considered:
- Does the datatype matter? A DataFrame full of floats, strings and booleans, respectively, will be tested to see how this compares to mixed data.
- Pandas 2.x includes the possibility to use “PyArrow” datatypes. How does this compare to the “Numpy” datatypes that have been used up to this point?
Does the type of data matter?
Starting with point 1 from the previous section, let’s find out if any of the file formats have any advantages, or weaknesses, when specific data is used in the DataFrame.
Filesize
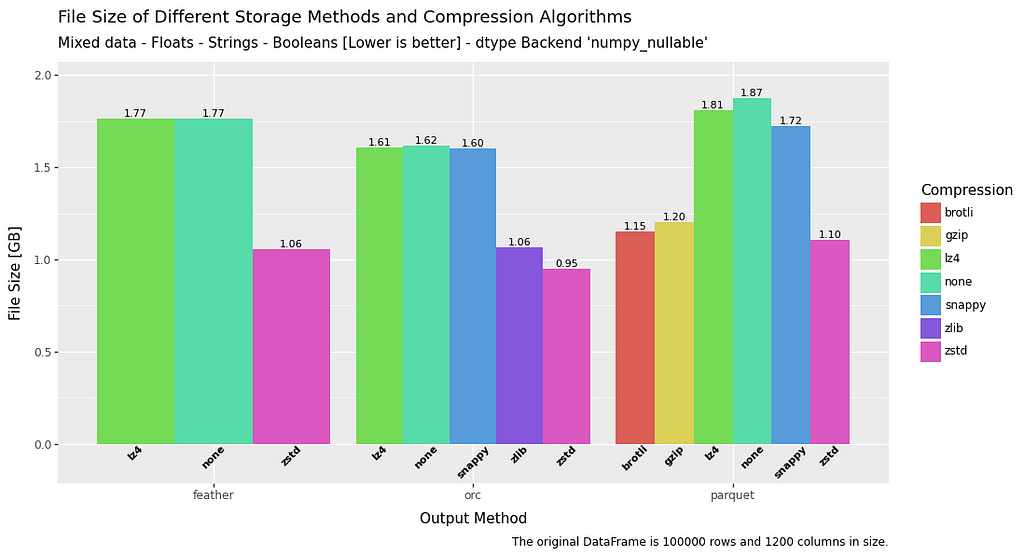
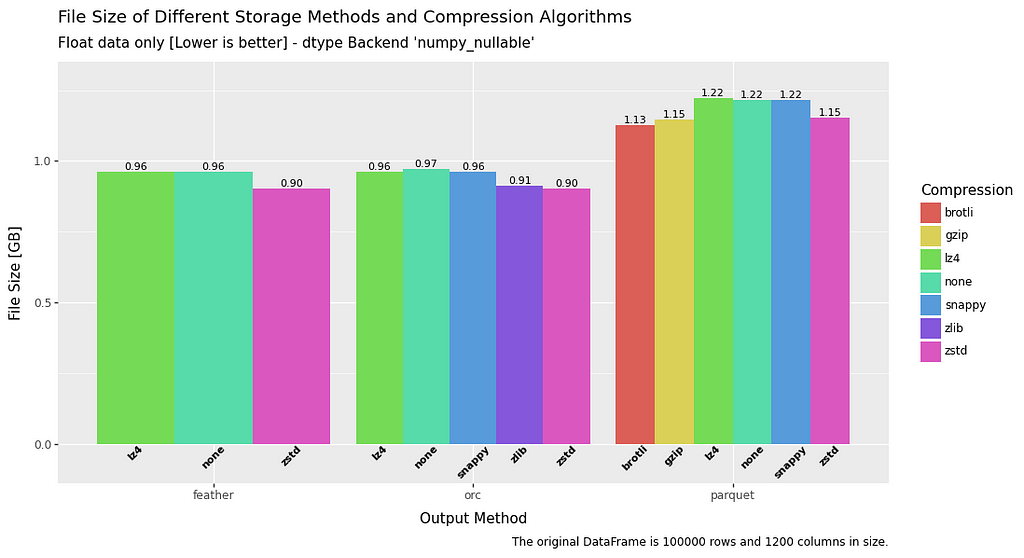
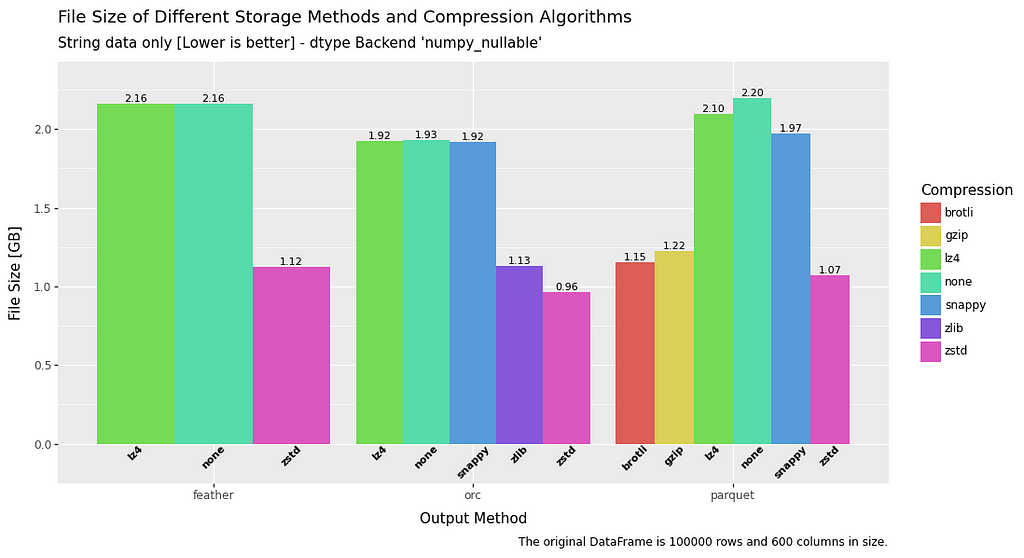
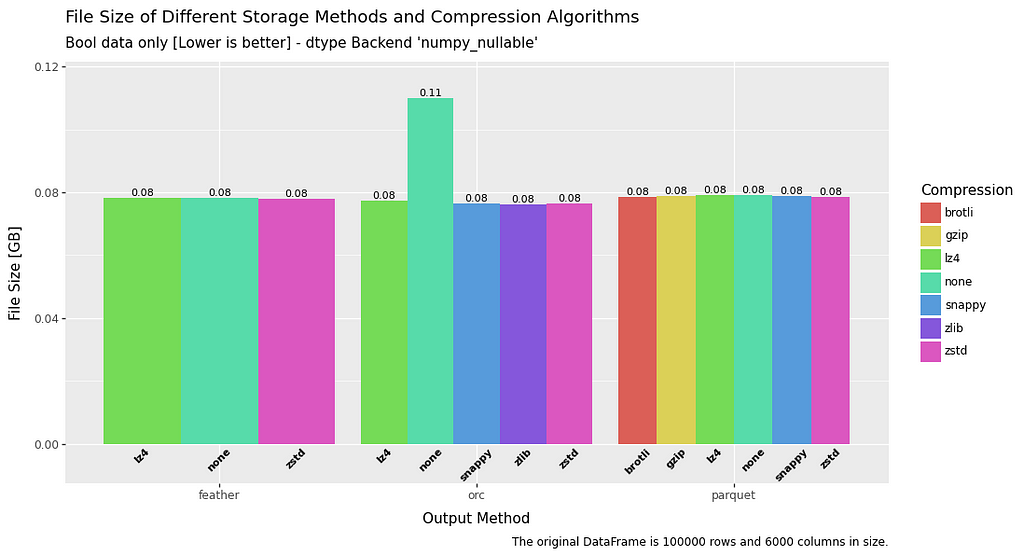
In terms of file size, across the board ZSTD has the superior compression ratio.
ORC comes out on top, but in reality feather and parquet are roughly comparable, with the notable exception of parquet when it comes to float data.
Execution Speed — Write
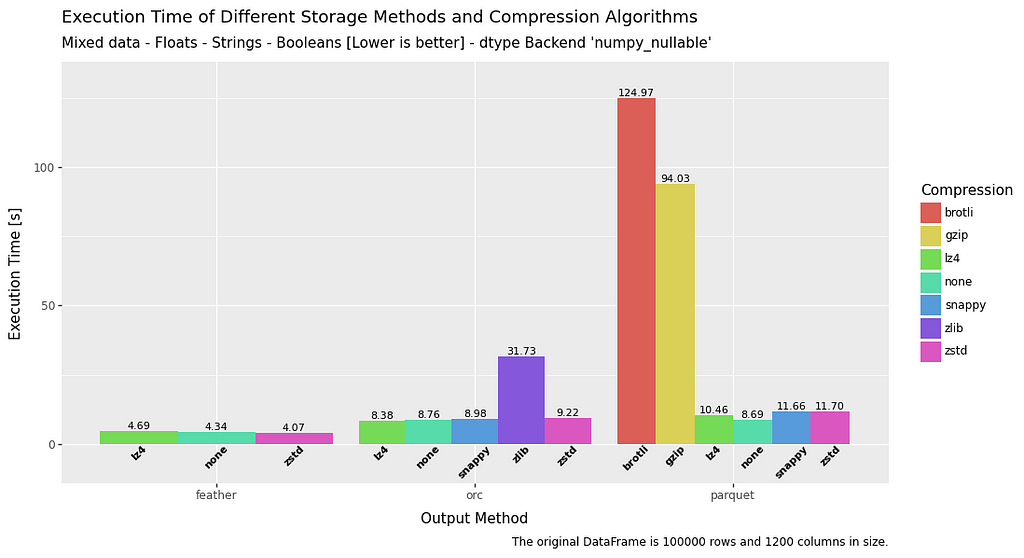
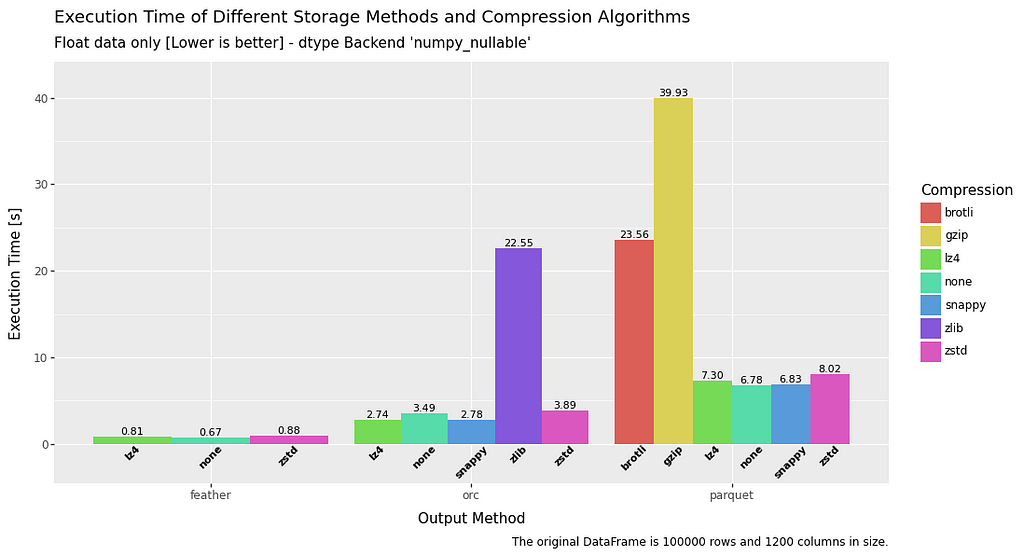
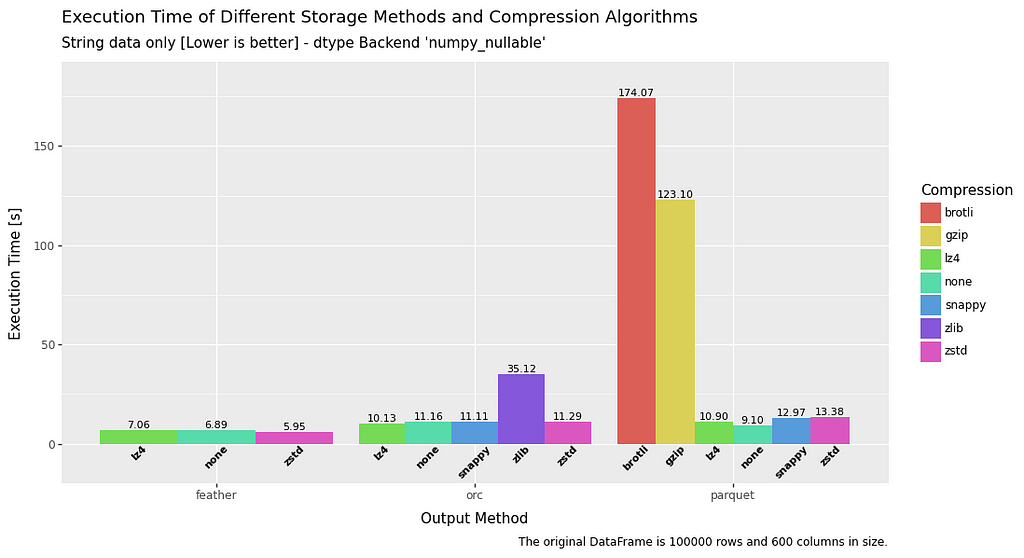
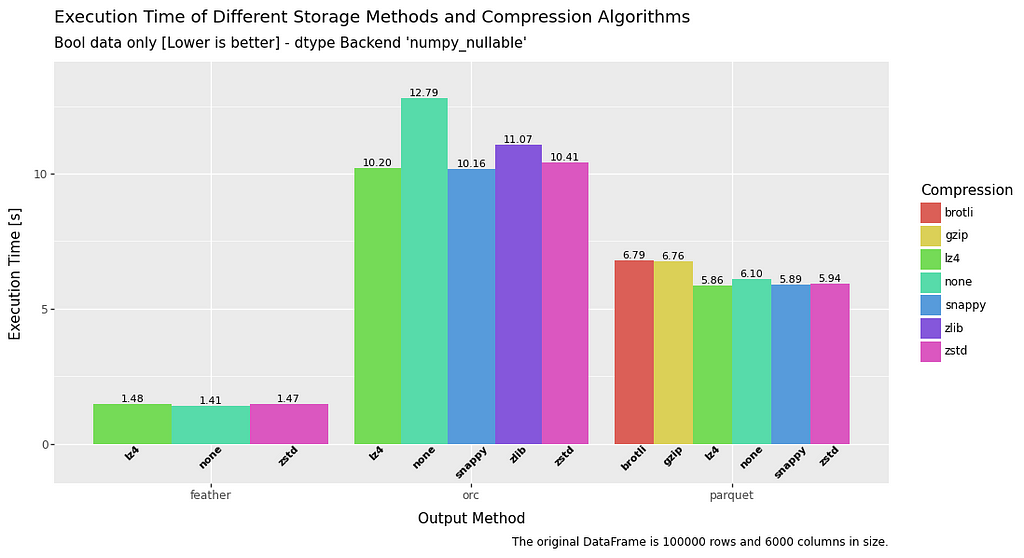
Write speed is quite interesting.
The standout result is that feather is at least twice as fast as the other methods, and sometimes significantly more. Boolean data seems to be a particular problem for ORC and parquet when compared to feather.
Float data again appears to be a weakness for parquet, and the same can be said for ORC with regard to boolean data.
A really mixed bag, but a convincing win for feather.
Execution Speed — Read
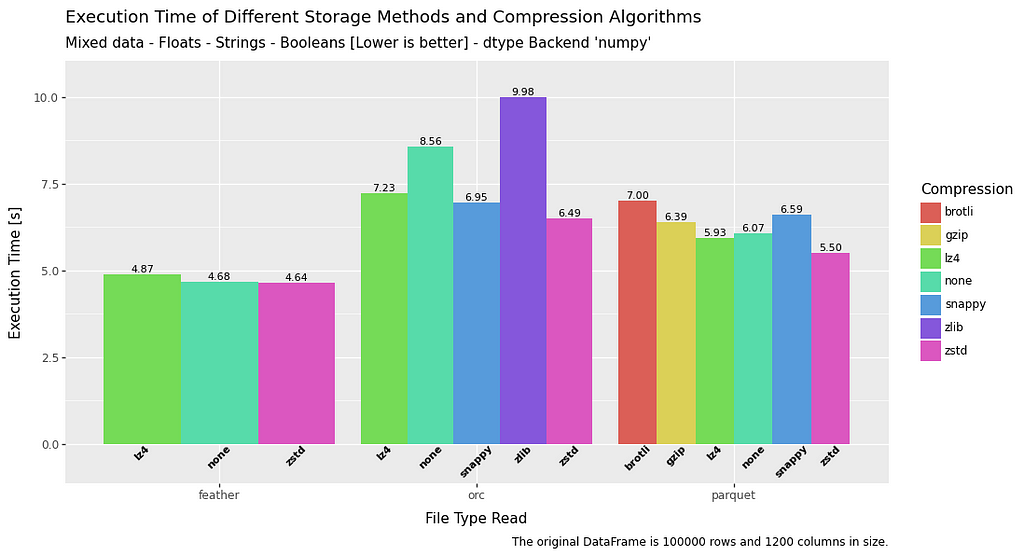
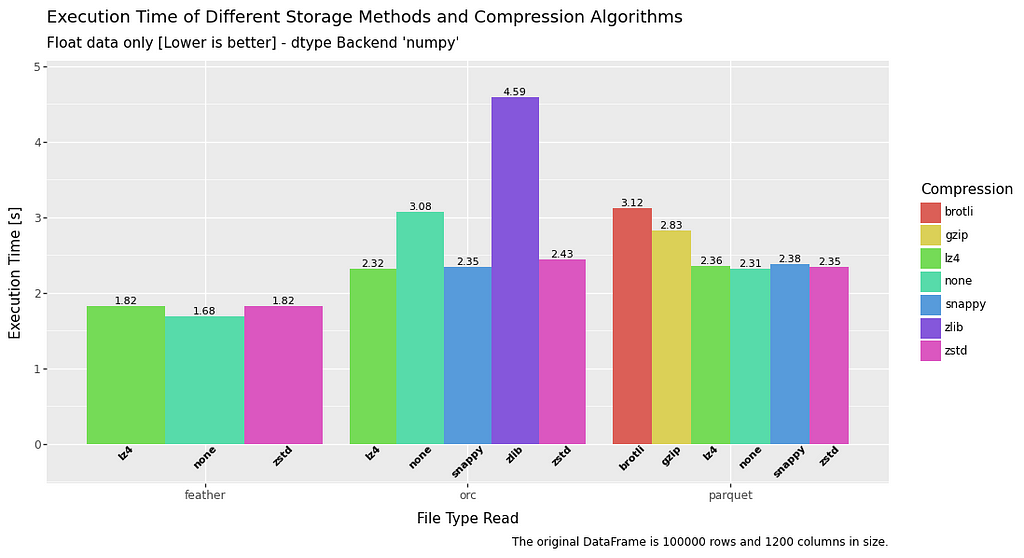
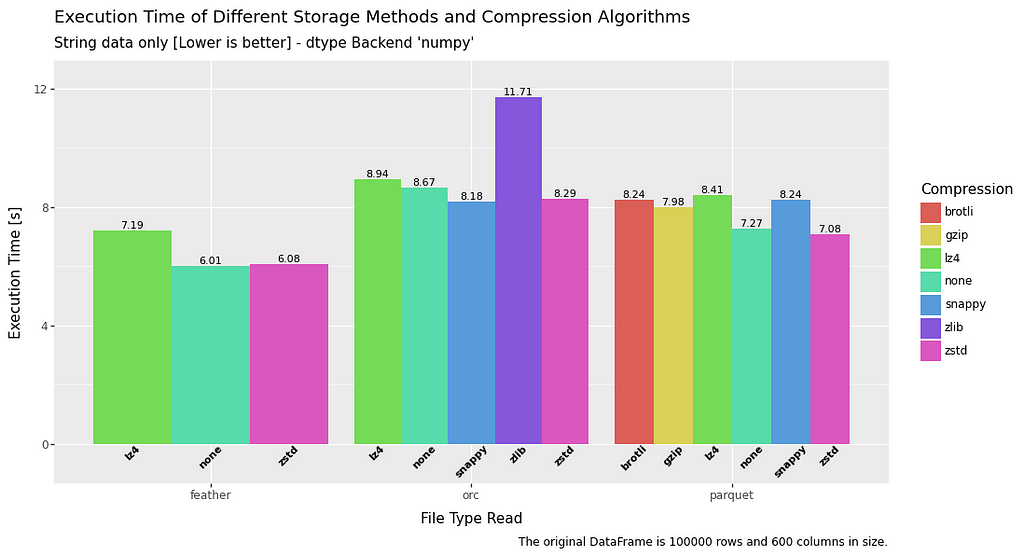
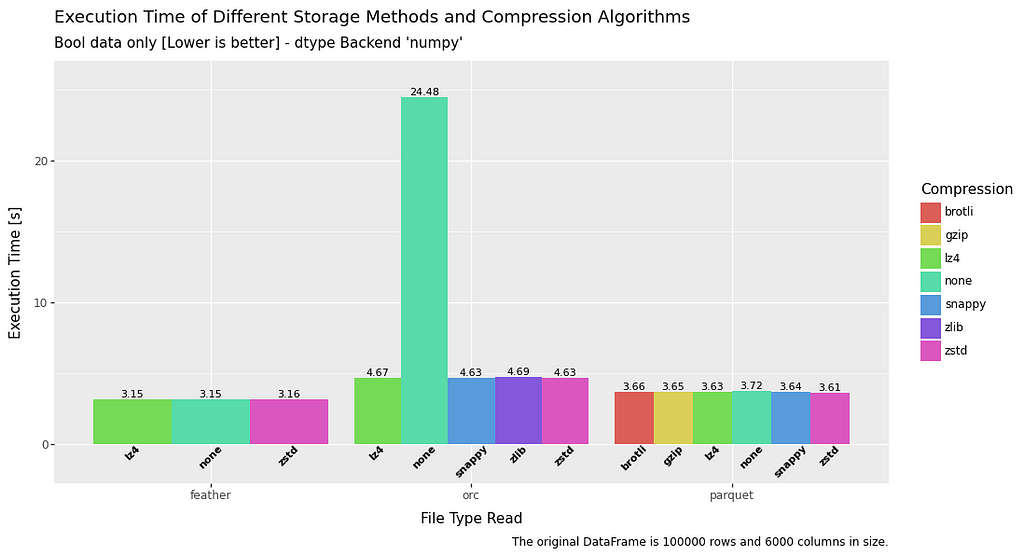
All in all, read time is pretty fast and consistent between the different file types across all datatypes. Feather has a slight advantage across the board, but nothing too extreme.
RAM usage — Write
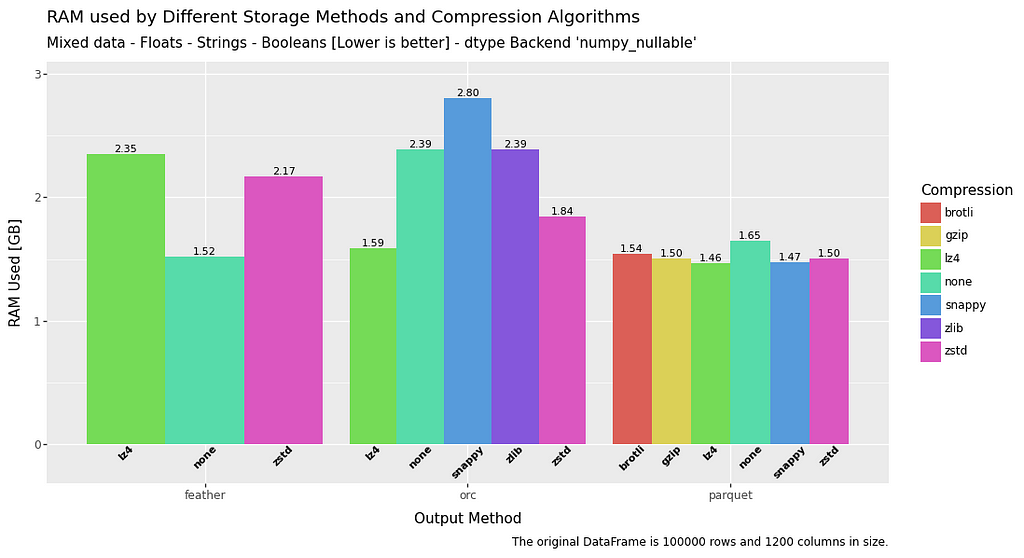
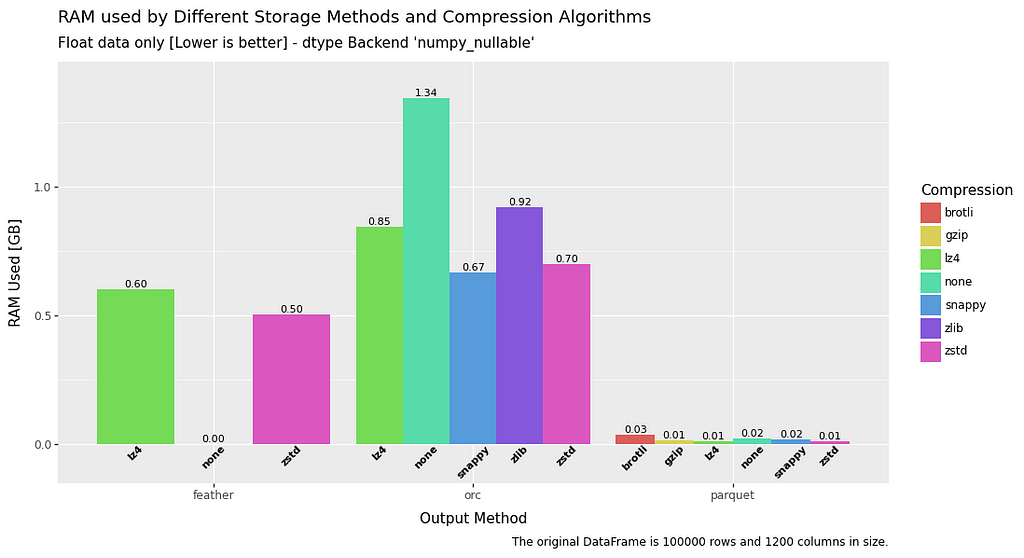
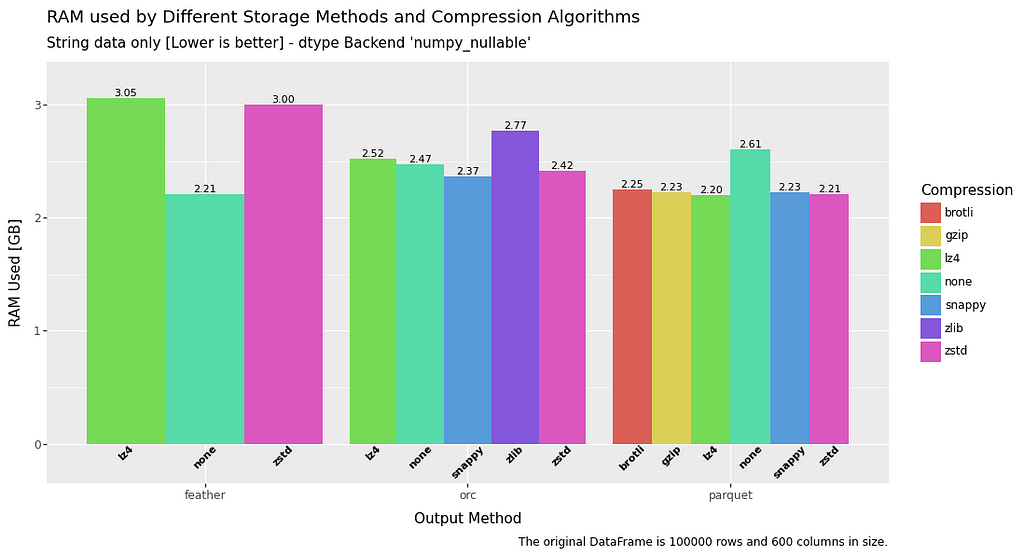
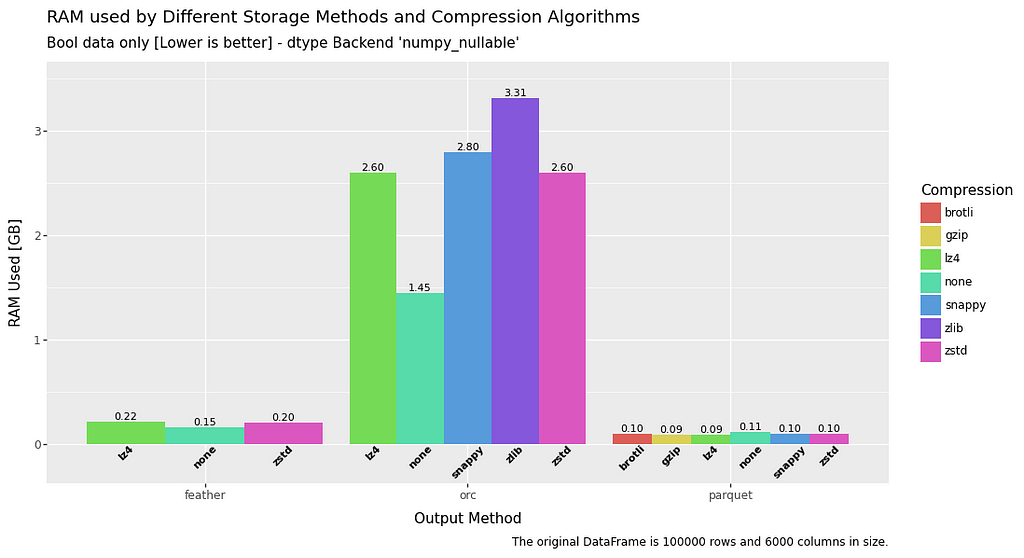
In terms of RAM usage on write, string data is consistent for all filetypes. However, when it comes to float or boolean data there is a significant advantage to be had by using parquet or uncompressed feather.
ORC is definately a little bit behind the pack for RAM write usage.
RAM usage — Read
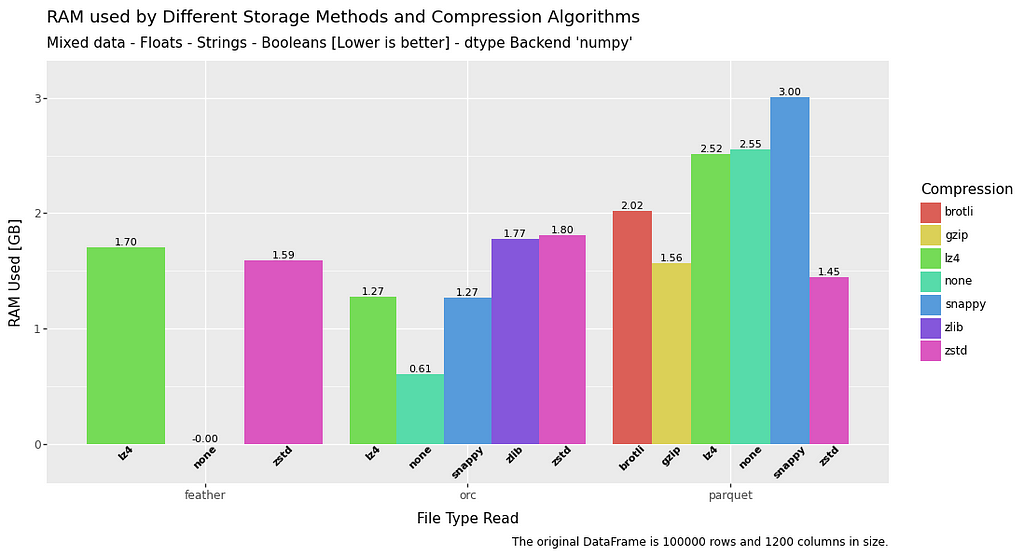
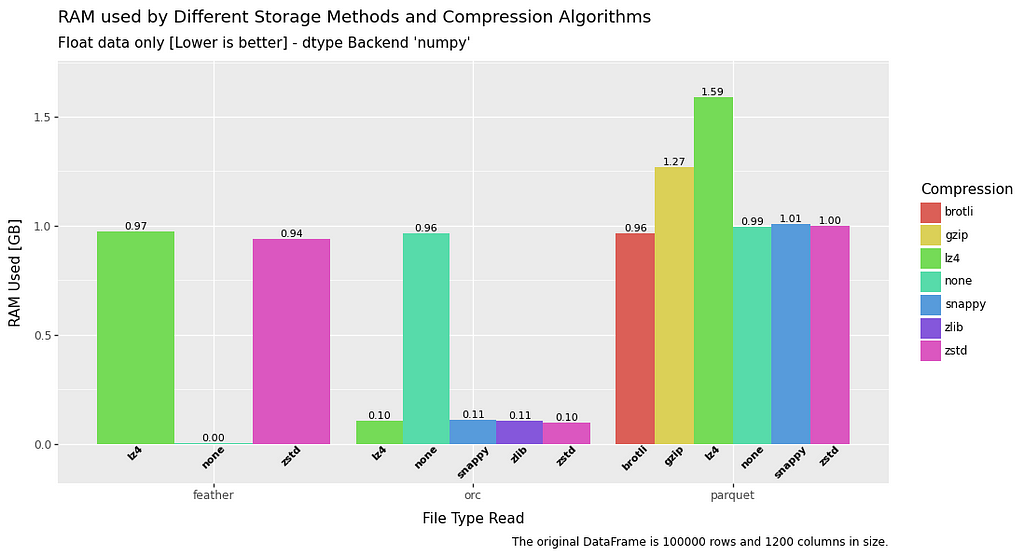
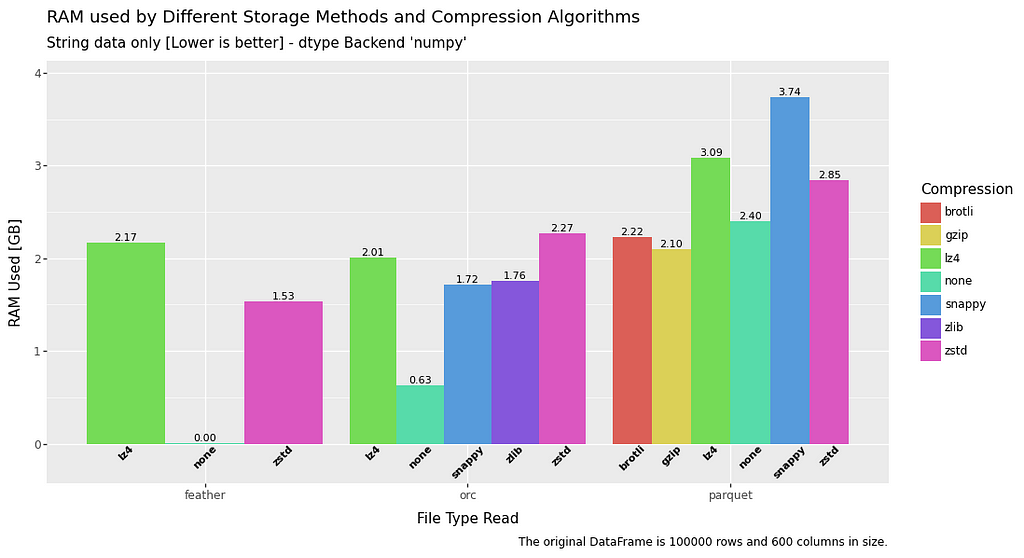
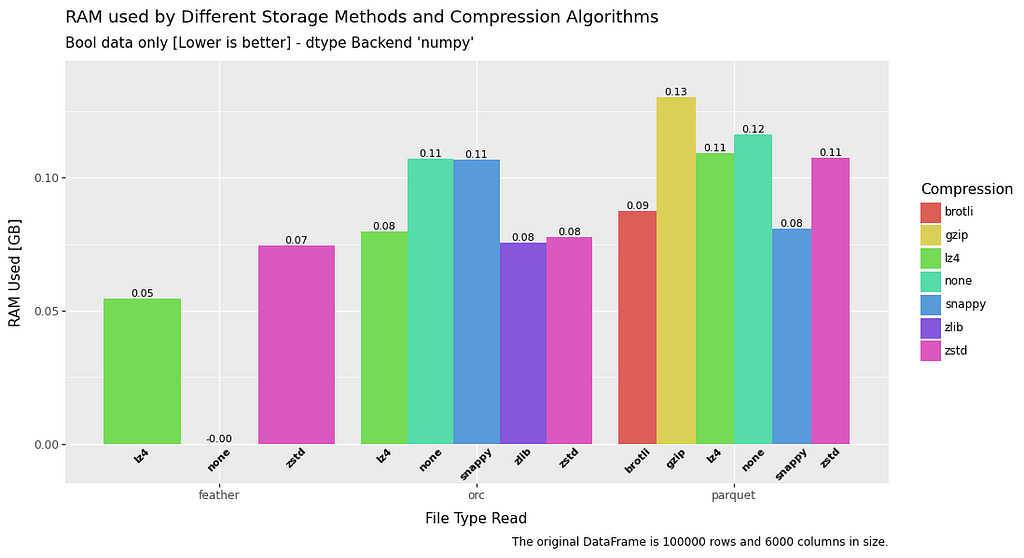
The RAM usage for read is a fairly mixed bag, and all file types perform roughly equivalently.
Some exceptions to this are feather data without compression which has no RAM overhead at all, and float data when utilising ORC.
Pandas 2.x with PyArrow Datatypes
One of the significant upgrades that came with the release of Pandas 2 is the inclusion of the ability to utilise PyArrow datatypes directly in DataFrames.
For example if I was to load a feather file using numpy datatypes:
df_numpy = pd.read_feather('dataframe.feather.zstd', dtype_backend='numpy_nullable')
…or I could use the new PyArrow backend, and load PyArrow datatypes:
df_pyarrow = pd.read_feather('dataframe.feather.zstd', dtype_backend='pyarrow')
As some of the formats, such as parquet and feather are based on PyArrow to some extent, this gives the potential of having much improved performance.
Let’s see what sort of difference it really makes.
PyArrow Comparison
As ZSTD compression has been consistently outperforming all other compression methods throughout this article. The next set of comparisons will exclusively use ZSTD as compression.
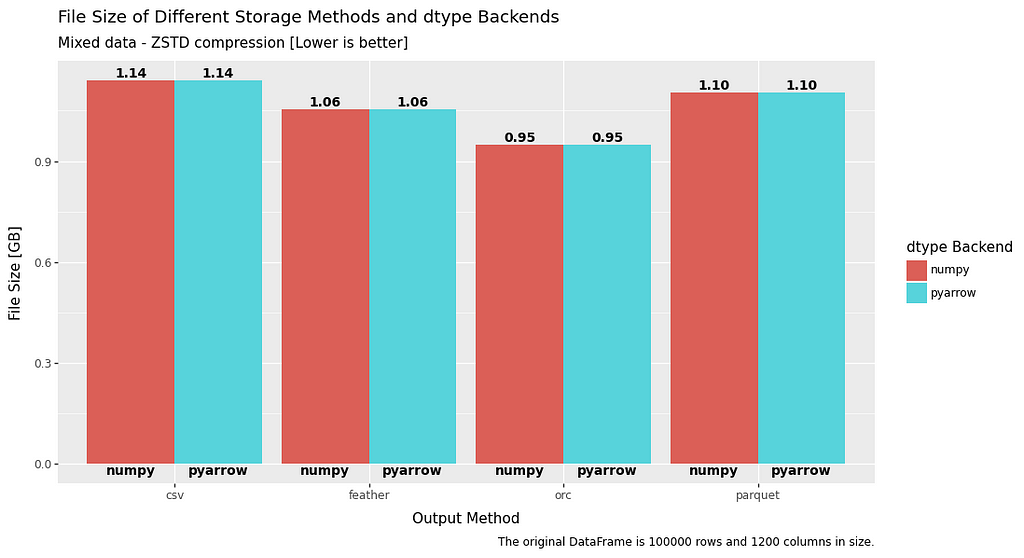
As would be expected there is no difference between the saved file sizes, so let’s move onto the execution time.
Execution time
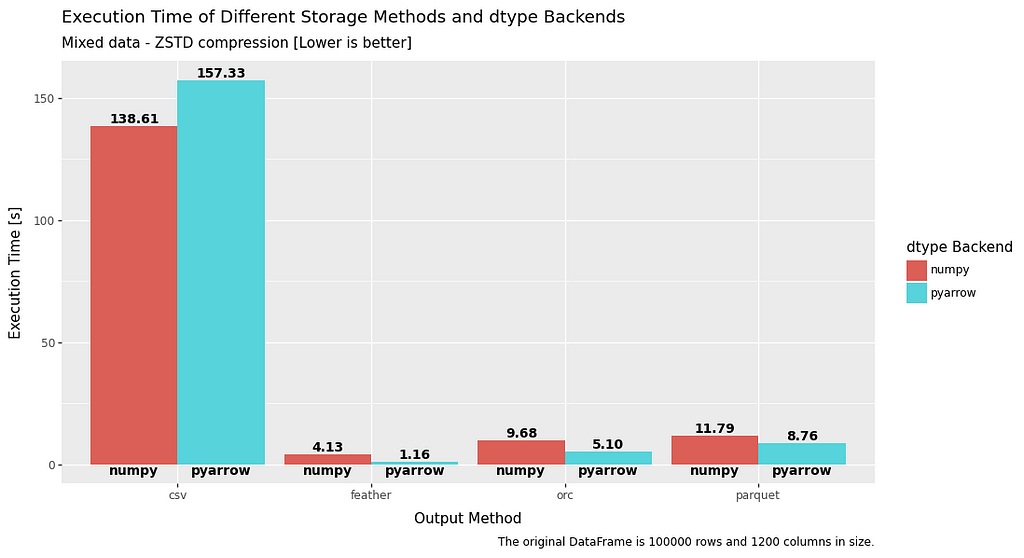
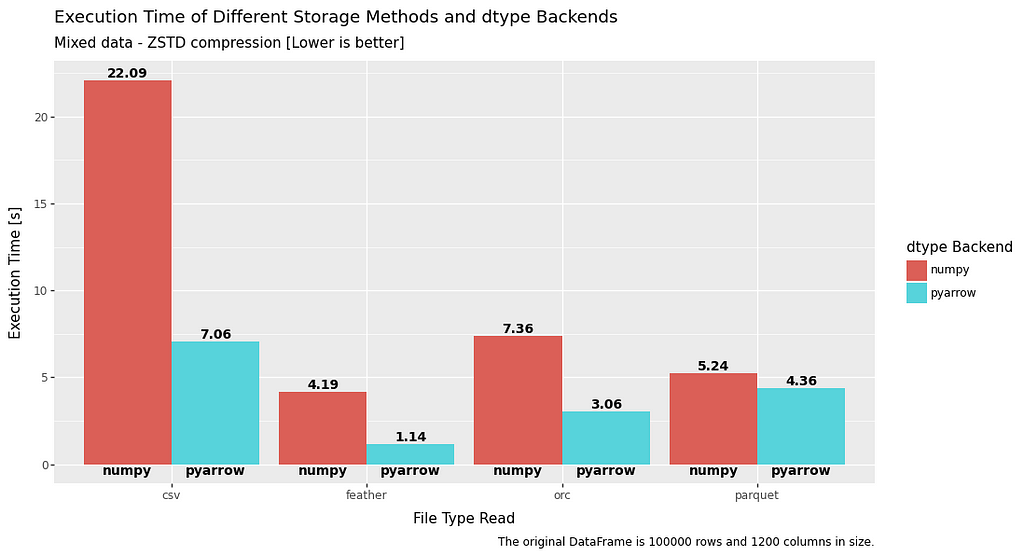
As is quite clear there is a significant advantage in both read and write time when using PyArrow datatypes. This is especially prevalent with ORC and feather file formats, which are at least twice as fast as when using numpy datatypes.
RAM usage
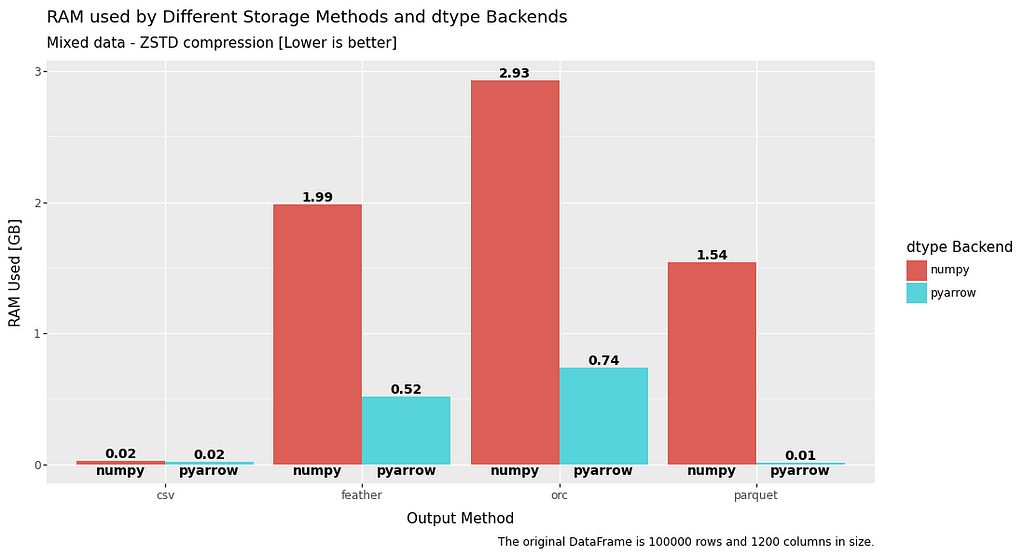
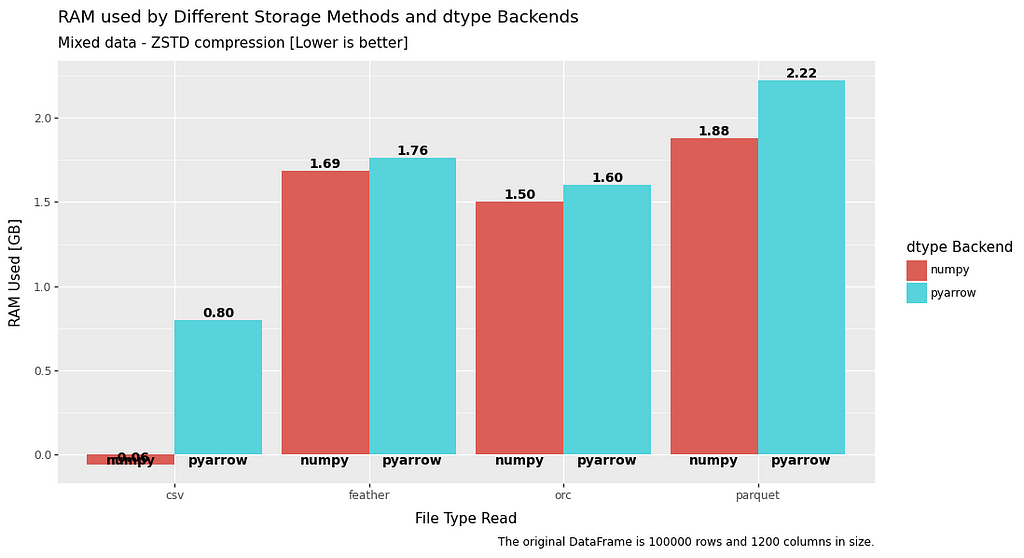
RAM usage is a mixed bag, with a significant advantage when it comes to write, but slightly worse read performance.
Quick analysis

In general CSV can be discarded. The only real exception is if RAM is very restricted in your particular use case, in which case, the severe disadvantage in execution speed may be worth it.
In general CSV can be discarded
However, generally it comes down to a choice between feather, ORC and Parquet.
Feather
Feather is generally an excellent choice. It outperforms the other formats quite consistently on read/write speed, and especially with regard to RAM usage on read if no compression is used.
[Feather] outperforms the other formats quite consistently on read/write speed
Feather is generally considered to be less feature rich than the other formats, but is obviously worth considering if speed of execution and RAM are primary concerns.
ORC
ORC is also a top performer. It doesn’t quite outdo feather in some categories, but is close enough to be relevant. More significantly, it consistently produces the highest compression ratio with ZSTD under all conditions.
[ORC] consistently produces the highest compression ratio
If ultimate compression ratio is your goal, without sacrificing too much in other areas, then ORC is a good bet.
Parquet
Parquet is generally considered a more feature rich version of feather, and is widely used in industry. It performs on a very similar level to ORC, sometimes slightly better, sometimes slightly worse. Although I would say ORC has a slight edge overall.
[Parquet] performs on a very similar level to ORC
Again, definitely worthy of consideration if your specific use case requires Parquets particular features.
Conclusion

To keep things simple this is what I recommend based on the results of this article:
- Only use CSV if the data you have will cause problems with RAM on read and write
- Always use PyArrow datatype rather than the numpy datatype if you can
- Always use ZSTD compression as it will result in high compression whilst also being fast
- Feather is generally the best performer, so use that if you can
- If you need the additional features of Parquet or ORC, then use one of those, you won’t lose anything significant compared to feather
- If you can’t use feather, but can freely choose between ORC and Parquet, go with ORC as it is generally slightly more performant
Remember, the results in this article are specific to the data specified earlier in the article. You may find for much smaller DataFrames, or even much larger DataFrames, the results vary from what is presented here.
However, I hope you now have a decent amount of data to make an informed decision as to which format suits your specific situation best.
Saving Pandas DataFrames Efficiently and Quickly — Parquet vs Feather vs ORC vs CSV was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Datascience in Towards Data Science on Medium https://ift.tt/UeRbJYr
via IFTTT


